最近迷上了爬虫技术
python 爬虫,目前我还在进一步学习阶段,有志同道合的兄弟们,可以一起探讨。
import requests
import os
from lxml import etree
if __name__ == "__main__":
parse = etree.HTMLParser(encoding="utf-8")
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(HTML, like Gecko) Chrome/98.0.4758.81 Safari/537.36'
}
url = "https://域名/index_4.html"
page_text = requests.get(url=url, headers=headers)
# 通用处理中文乱码的解决方案
# img_name = img_name.encode('iso-8859-1').decode('gbk')
page_text.encoding = page_text.apparent_encoding
page_text = page_text.text
tree = etree.HTML(page_text, parser=parse)
li_list = tree.xpath('//ul[@ class = "clearfix"]/li')
if not os.path.exists('文件夹'):
os.mkdir('文件夹')
for li in li_list:
img_name = li.xpath('./a/img/@alt')[0] '.jpg'
img_src = "https://域名/" li.xpath('./a/img/@src')[0]
img_data = requests.get(url=img_src, headers=headers).content
with open('文件夹/' img_name, 'wb') as fp:
fp.write(img_data)
print(img_name)
测试结果:

视频号小店30元及以下商品需设置包邮服务
日前,腾讯发布公告称,为营造视频号带货良好环境,规范商家经营行为,保障用户合法权益;现平台针对低价商品调整发布规范,30元(包含)以下的商品需要设置包邮服务(包括港澳台、海外和偏远地区)。腾讯提醒,即日起至2023年6月20日,商家需自行检查小店店铺已上架的商品,如有低于30元且没有设置包邮的商品需进行修改;如商家未在规定时间内整改,平台将按照违规商品下架,并不能在原有链接上修改重新提交审核。站长网2023-06-13 22:27:210000华为昇思已使能孵化超20个大模型
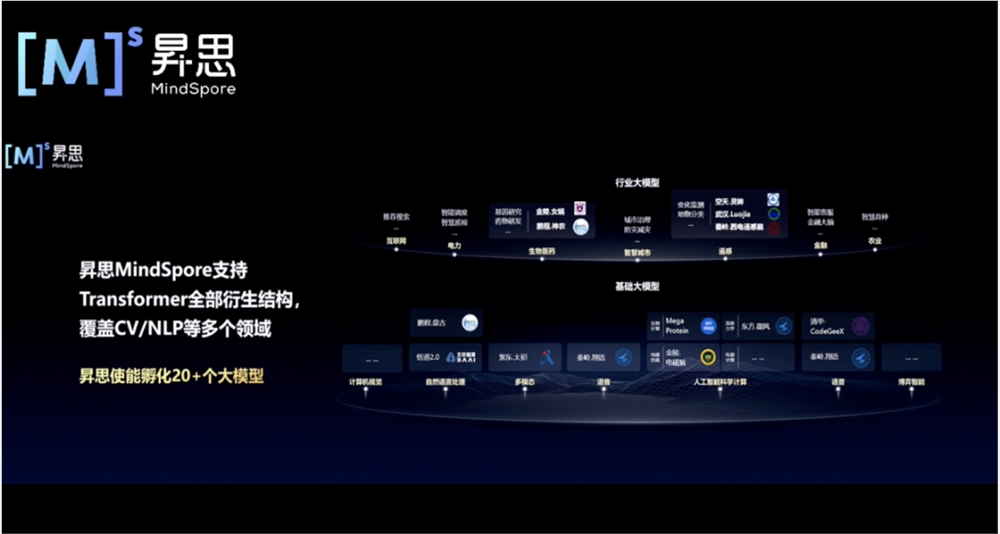
今天在上海举办的人工智能框架生态峰会2023上,昇思MindSpore2.0全新升级。昇思MindSpore2.0的升级包括六个方面,分别是易用性提升、原生大模型支持、AI4S融合框架、多后端统一推理、数据处理提升和机领域扩展库方面。据华为官方消息,昇思已使能孵化超过20个大模型,并且到年底还希望使能能够达到40到50个大模型的孵化能力。站长网2023-06-20 16:17:500001巴菲特旗下伯克希尔·哈撒韦减持比亚迪H股至10.90%
据据港交所文件,巴菲特旗下投资公司伯克希尔·哈撒韦将其持有的比亚迪H股减持至10.90%,此前为11.13%。2008年9月,巴菲特以每股8港元的价格认购2.25亿股比亚迪的股份,当时比亚则成为巴菲特唯一持有并重仓的中国公司。截止今日收盘,比亚迪股价上涨0.18%,报227.8港元,总市值6632亿港元。站长网2023-04-12 13:38:210000直逼GPT-4开源模型大泄漏,AI社区炸锅!Mistral CEO自曝是旧模型,OpenAI再败一局?
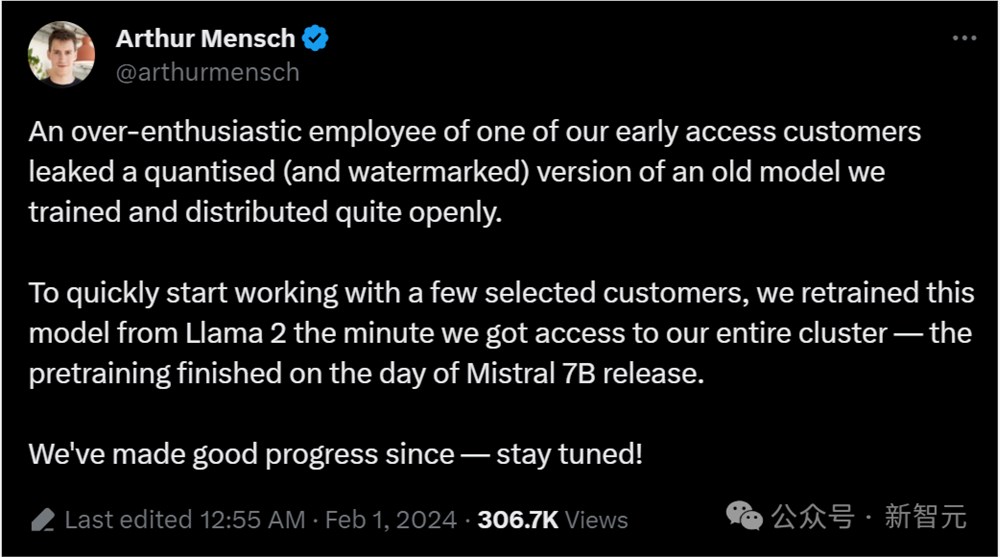
【新智元导读】这几天引发了AI社区大讨论的逼近GPT-4性能的泄漏模型「miqu」,的确是Mistral公司训练的一个旧模型的量化版。此前,冲上各大榜单的这个开源模型引发开发者热议,开源AI或已进入关键时刻。破案了!让众多网友抓心挠肝的开源新模型「miqu」,的确是Mistral训练模型的一个旧的量化版本,是在Llama2上重新训练的。今天,MistralCEO亲口确认了这一点。站长网2024-02-02 18:04:190000Runway又出新功能!可将多个Gen 2生成的视频合成到一个场景中
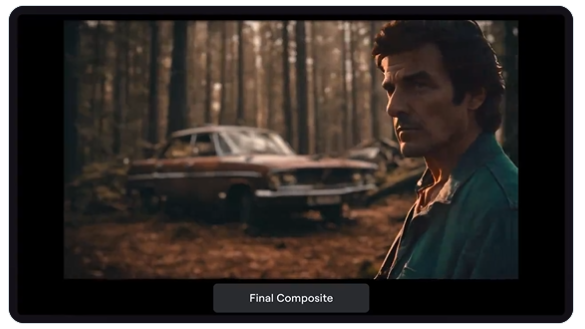
继运动笔刷,文字生成语音功能后,Runway又推出了新功能,支持将多个Gen2生成的视频合成到一个场景中,这样能创造出更丰富的场景内容视频!这一功能让用户能够将人物、风景画面、建筑等元素融合到一个场景中,形成更丰富的场景内容,有点类似于Photoshop的图层功能。Gen-2合成工作流程如下:1、在Gen-2中生成视频,例如,一个视频展示前景主题,另一个视频展示最终合成的期望背景。站长网2023-12-22 09:41:310000