Salesforce新AI模型可改善数据分析 XGen-7B基准测试超越Meta的LLaMA-7B
随着对AI工具的需求增加,对能够完成更多任务的系统的需求也越来越大。
企业可以通过拥有像ChatGPT或Bard这样的聊天界面来受益,这些界面能够对冗长的文件进行摘要或筛选客户数据以获取见解。但要执行这些任务,模型需要经过大量数据的训练。而企业通常选择了更小、更具成本效益的模型,问题在于这些模型无法很好地处理这些任务。
像Meta的LLaMA、Falcon-7B和MPT-7B等开源模型,其最大序列长度约为2,000个token,使得它们难以处理像文件这样的冗长非结构化数据。
这也是Salesforce推出的一系列大型语言模型XGen-7B的原因,XGen-7B在长达8,000个token的序列上进行训练,因此更容易处理冗长的文档输入,总共可处理1.5万亿个token。
Salesforce的研究人员使用Salesforce内部的库JaxFormer以及公共领域的教学数据对这一系列70亿参数的模型进行训练。
与LLaMA、Falcon和Redpajama等开源模型相比,所得到的模型在性能上达到或超过了它们。
Salesforce的AI研究人员表示,使用Google Cloud的TPU-v4云计算平台,在1万亿个token上训练这个模型只需花费15万美元。
XGen-7B基准测试亮眼
Salesforce的模型在一系列基准测试中取得了令人印象深刻的成绩,在许多方面都超过了受欢迎的开源大型语言模型。
在对“Measuring Massive Multitask Language Understanding(MMLU)”基准测试进行测试时,XGen在四个测试类别中有三个类别取得了最高分,而且在加权平均分中也是最高的。只有Meta的LLaMA在人文学科方面的MMLU测试中比XGen得分更高。
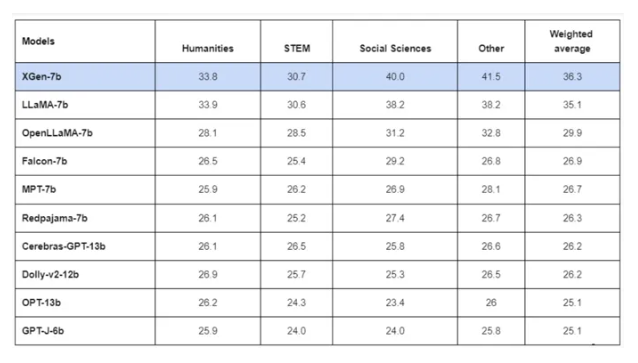
在同一基准测试的零样本测试中,XGen取得了类似的结果,但在人文学科方面仍然不及LLaMA。
就整体零样本测试而言,XGen只在“TruthfulQA”基准测试中超过了其他模型。在包括ARC_ch、Hella Swag和Winogrande在内的基准测试中,Meta的LLaMA取得了更好的结果。
然而,在代码生成任务上,XGen在评估基准测试的pass@1指标上超过了LLaMA和其他模型,得分为14.20,而LLaMA只有10.38。
在长序列任务中,Salesforce的这个新AI模型表现最出色,在SCROLLS基准测试的QMSum和GovReport数据集上得分非常高。
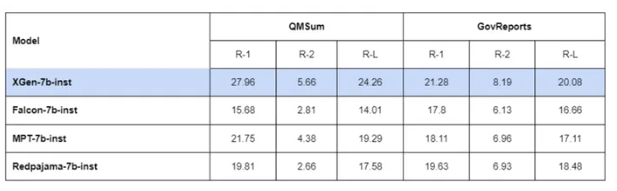
不过,Salesforce的研究人员指出,由于XGen模型没有在相同的教学数据上进行训练,“它们不是严格可比较的”。
XGen-7B系列
Salesforce的研究人员创建了三个模型——XGen-7B-4K-base、XGen-7B-8K-base和XGen-7B-inst。
XGen-7B-4K-base能够处理8000亿个上下文token,它是在2,000个token,后来又是4,000个token上进行训练的。它以Apache-2.0许可发布,这意味着可以根据不同的许可协议分发派生作品,但所有未修改的组件必须使用Apache2.0许可。
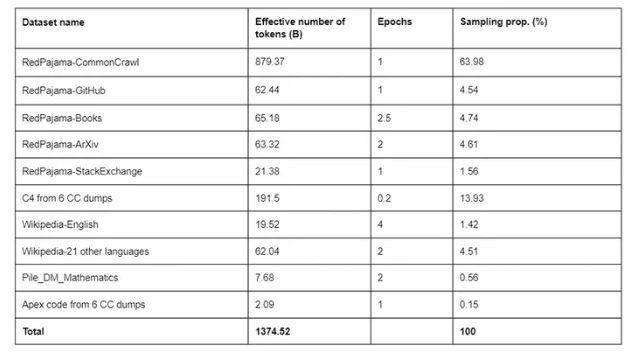
XGen-7B-8K-base在之前提到的模型的基础上增加了3000亿个token,使其总的上下文理解能力达到了1.5万亿个token。这个模型也以Apache2.0许可发布。
XGen-7B-inst在公共领域的教学数据上进行了微调,包括databricks-dolly-15k、oasst1、Baize和与GPT相关的数据集。该模型在4,000个和8,000个token上进行了训练,仅用于研究目的。
为了训练这些模型,Salesforce的研究人员采用了两阶段的训练策略,每个阶段使用不同的数据混合。
团队解释说:“对于C4,我们使用C4流程处理了6个Common Crawl转储,并通过仅保留具有相同URL的文档中的最新时间戳,跨不同的转储去重了文档。我们训练了一个线性模型,将C4数据分类为类似于维基百科的文档和随机文档。然后,我们选择了前20%的类似于维基百科的文档。”
然后,将Salesforce和Hugging Face创建的代码生成模型Starcoder添加到支持代码生成任务。然后将Starcoder的核心数据与前一阶段的数据混合。
然后使用OpenAI的tiktoken对模型的数据进行token化,随后添加了连续空白和制表符的额外token。
虽然XGen的训练过程得到了一系列功能强大的AI模型,但也存在一些缺陷。Salesforce指出,该模型仍然存在幻觉问题。
有关XGen-7B的更多信息,Salesforce在其博客上发布了一篇详细的文章。模型的代码库可以在GitHub上找到,模型的检查点可以在Hugging Face上找到。
上下文至关重要
能够理解更长输入的模型对企业来说可能是一个巨大的优势。
Salesforce的研究人员表示,大量的上下文“使得预训练的语言模型能够查看客户数据并对有用的信息查询做出回应”。
对于聊天机器人应用来说,更多的上下文意味着更多的对话。Salesforce并不是唯一一个研究这一概念的组织。Anthropic是由OpenAI的前员工创办的新兴AI初创公司,最近扩大了其旗舰应用Claude的上下文长度。
Claude现在可以用于从多个冗长的商业文件或书籍中获取信息,用户可以询问有关数据的问题。
目前的模型在增加上下文长度方面存在困难。当ChatGPT和Bing的AI聊天等应用开始出现时,用户发现他们在单个对话中使用模型的时间越长,模型的回应变得越来越不稳定。这是由于模型无法处理较长的上下文长度,导致混淆和产生幻觉。
XGen-7B项目网址:https://blog.salesforceairesearch.com/xgen/
淘宝店播大爆发,已有4000家GMV破千万
淘宝商家店播的机会来了“如今的淘系直播对很多商家来说不再是渠道运营,它是一个全新的具有超强爆发力的品牌竞争力以及生意爆发的加速器。”淘天集团阿里妈妈市场部总经理穆尔指出。9月6日举办的2023阿里妈妈m峰会披露,今年以来,淘系已经形成了店铺、直播和内容三大中心,这三大中心为品牌实现全年生意的多频爆发。而这三者的协同、融合,已然成为了商家获取增量的关键。站长网2023-10-13 16:13:100000X 正式推出音频和视频通话功能 迈向 “一切应用程序” 的目标
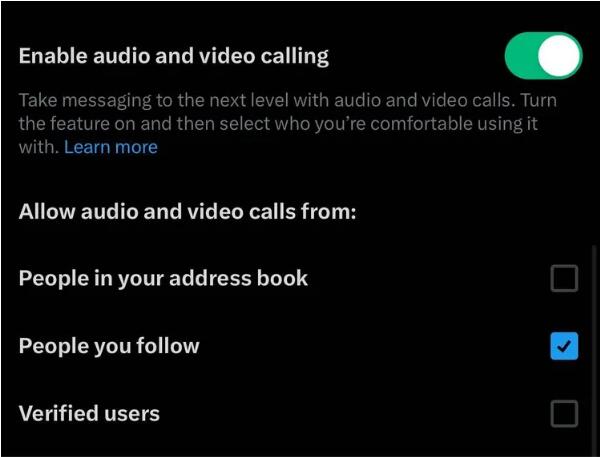
据国外媒体报道,X(以前称为Twitter)平台正在推出音频和视频通话功能。一些用户在打开应用程序时收到了一条通知,内容是:“音频和视频通话就在这里!”此外,应用程序的设置中新增了一个“启用音频和视频通话”切换按钮,用户可以选择“打开该功能,然后选择您愿意与谁一起使用它。”该功能包括仅允许来自地址簿中的人、您关注的人、经过验证的用户或全部三者进行音频和视频呼叫的选项。站长网2023-10-26 09:55:210001华硕计划推出基于英伟达芯片构建的 AI 系统服务 AFS Appliance:企业数据安全可控
华硕计划推出一项服务,让企业能够充分利用生成式人工智能的潜力,同时保持对其数据的控制权。这项名为AFSAppliance的服务的新颖之处在于所有硬件将安装在客户自己的设施中,以维护安全性和控制权。这个基于英伟达公司芯片技术构建的AI计算平台将由华硕运营和更新数据。站长网2023-05-31 11:46:510000抖音成中国赢家!2024全球科技品牌价值榜公布
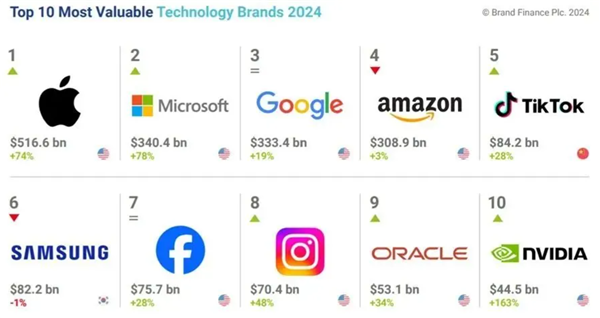
科技巨头风云变幻,BrandFinance重磅发布2024全球科技品牌价值100强榜单。令人瞩目的是,中国品牌抖音(TikTok)强势崛起,以841.99亿美元的品牌价值首次跻身前五强。值得一提的是,抖音(TikTok)的品牌价值相较去年激增28.2%,成为榜单中增长最快的品牌之一,彰显其在全球市场中的蓬勃发展。站长网2024-10-07 21:37:580000谷歌修改“有用内容更新”政策 调整对AI生成内容的立场
文章概要:-谷歌最新“有用内容更新”旨在区分内容是为搜索引擎编写还是为用户编写,强调了人性化内容。-谷歌承认监管人工智能生成内容存在困难,并强调内容应以人为本。-OpenAI删除了低准确性的AI识别器,计划研究更有效的技术以区分人工智能生成的内容。站长网2023-09-18 10:57:550000