AI时代,你需要了解的国外 12 个主流大语言模型
站长之家(ChinaZ.com) 导语:如今,AI大语言模型泛滥,这让人眼花缭乱。本文中,站长之家带大家着眼于一些国外撼动人工智能领域的重要模型,包括这些大语言模型的开发商、参数以及使用用例情况。下面一起来看看吧。

1、ChatGPT
开发商:OpenAI
https://openai.com/
参数:未知
ChatGPT是真正激发了主流公众对人工智能迷恋的应用程序。
ChatGPT 于2022年11月发布,是一个界面应用程序,允许用户向其提问并生成响应。
它使用 InstructGPT 和 GPT3.5的组合启动,后来看到强大的GPT-4为该应用程序的高级版本提供支持。
在微软投资OpenAI 并获得该应用程序的访问权限后,ChatGPT 已成为微软一系列产品的基础。
ChatGPT 是一个封闭系统,这意味着 OpenAI 保留对应用程序的完全控制和所有权。OpenAI 将 GPT-4的参数级别保密。
用例
文本生成和摘要– ChatGPT 可以通过详细的响应生成类似人类的文本。除了回答各种问题外,它还具有有效的摘要能力,能够解析大量信息以提供简洁、易于理解的摘要,使其成为将复杂内容提炼为更易于管理的形式的强大工具。
代码生成- ChatGPT 可以跨多种编程语言生成代码,提供编码问题的解决方案,并帮助调试和演示编码实践。其结果虽然总体上可靠,但仍应审查其准确性和优化性。根据Stack Overflow 调查,ChatGPT 是开发者中最受欢迎的人工智能工具。
操作机器人——微软的工程师团队展示了让ChatGPT 控制机器人的可能性。在演示中,OpenAI 的语言模型连接到机械臂,并负责解决一些难题。当用户的指令不明确时,ChatGPT 会向研究人员询问澄清问题。它甚至为另一个实验中控制的无人机编写了代码结构。
为立法者总结法案——国会工作人员正在使用 ChatGPT。国会工作人员获得了大约40个 ChatGPT 许可证,这是使用 GPT-4的20美元高级版本。尽管有报道称工作人员正在使用该工具来创建和总结内容,但没有透露 ChatGPT 许可证的用途。
2、LLaMA
开发者:Meta、FAIR
https://ai.facebook.com/
参数:7~650亿
LLaMA – 代表大型语言模型元人工智能,专为研究人员和开发人员制作模型而设计。LLaMA 是一个开源模型,其设计比 GPT-3等模型更小。它是为缺乏开发语言模型的计算能力的用户而设计的。
自2023年2月下旬发布以来,研究人员经常对 LLaMA 进行微调,以创建其他语言模型,例如Vicuna。
用例
开源模型开发——LLaMA 已经为各种开源 AI 模型奠定了基础,包括Dolly、Alpaca和Gorilla等。随着研究人员和开发人员纷纷涌向人工智能模型,LLaMA 就是为了修改而生的。事实证明,LLaMA 的70亿参数版本非常受欢迎,因为它的尺寸意味着它运行所需的计算能力更少。
访问 LLaMA 代码 - https://github.com/facebookresearch/llama
3、I-JEPA
开发商:Meta、FAIR
https://ai.facebook.com/
参数:未知
I-JEPA是 Meta 于2023年6月发布的 AI 模型。模型本身并不是明星,而是它的构建方式:使用新的架构。
JEPA 方法可以预测缺失的信息,类似于人类的一般理解能力,这是生成式 AI 方法无法做到的。
Meta的首席AI科学家Yann LeCun不断提出深度学习AI模型可以在不需要人工干预的情况下了解周围环境的想法。JEPA 方法符合这一愿景,并且不涉及与应用计算密集型数据增强来生成多个视图相关的任何开销。
用例
从图像进行自我监督学习- I-JEPA(图像联合嵌入预测架构)创建主题的内部模型并比较图像的抽象表示,而不是比较单个像素本身。
I-JEPA 可以有效地学习该信息并将其应用到各种应用程序中,而无需进行大量的微调。
访问 I-JEPA 的模型代码和检查点 - https://github.com/facebookresearch/ijepa
4、PaLM2
开发商:谷歌
https://ai.google/
参数:3400亿(据报道)
PaLM2是 Google 的旗舰语言模型。该模型在公司年度 I/O 大会上推出,支持100多种语言,并针对特定领域的应用程序进行了微调。
PaLM 有多种尺寸 - 每种尺寸均以动物命名,以代表其尺寸。壁虎是最小的,然后是水獭、野牛,最后是最大的独角兽。
用例
聊天机器人改进– PaLM 现在为 Bard 提供支持,Bard 是 Google 对 ChatGPT 的回应。PaLM 使 Bard 能够生成文本和代码以及总结文档。
音频生成和语音处理– PaLM2与音频生成模型结合使用时,可用于生成文本和语音以进行语音识别和语音到语音翻译。与 AudioLM 结合使用时,PaLM2可以利用大量文本训练数据来协助完成语音任务。谷歌认为,在音频生成系统中添加纯文本大型语言模型可以改善语音处理,并且在语音翻译任务方面优于现有系统。
医疗保健应用– 在 PaLM2微调并应用于特定部门的示例中,Med-PaLM-2展示了该模型的多功能性。用户可以提示模型通过图像(例如 X 射线)确定医疗问题。据谷歌研究人员称,Med-PaLM-2的不准确推理减少了九倍——接近临床医生回答同一组问题的表现。
5、Auto-GPT
开发者:Auto-GPT开发团队
https://news.agpt.co/meet-the-team/
参数:未知
Auto-GPT是 Autonomous GPT 的缩写,是一个开源项目,试图为互联网用户提供强大的语言模型。Auto-GPT 基于 OpenAI 的GPT-4构建,可用于自动化社交媒体帐户或生成文本等用例。
该模型于2023年4月推出后在网上广受欢迎,前特斯拉人工智能首席执行官安德烈·卡帕蒂 (Andrej Karpathy) 等人都称赞该模型的能力。
用例
Twitter AI 帐户– 尽管埃隆·马斯克 (Elon Musk) 试图取消机器人帐户,但 Auto-GPT 仍可用于为 Twitter 个人资料提供支持。Auto-GPT 用于为IndiepreneurGPT帐户提供支持并自动通过该帐户发送推文。
自动化一般流程– Auto-GPT 专为实验而设计。到目前为止,开发人员已经使用该模型来做一些事情,例如自动订购披萨、计划旅行或预订航班。然而,其背后的团队警告说,它还没有“完善”,并且“在复杂的现实业务场景中可能表现不佳”。
访问 Auto-GPT - https://github.com/Significant-Gravitas/Auto-GPT
6、Claude
开发商:Anthropic
https://www.anthropic.com/
参数:未知(尽管 Anthropic 的宪法 AI 论文提到了 AnthropicLM v4-s3,它拥有520亿个参数)
将Claude视为 ChatGPT 明智的表弟。Anthropic 由前 OpenAI 员工创立,他们在与微软的密切关系上留下了分歧。
Anthropic 随后开发了 Claude,这是一款聊天机器人应用程序,与 ChatGPT 没有太大不同,除了一件事——更加关注安全性。
Claude使用宪法人工智能,这是由 Anthropic 开发的一种方法,可以防止其产生潜在有害的输出。该模型被赋予了一套需要遵守的原则,几乎就像赋予它一种“良心”。
在撰写本文时,Claude2是最新版本。Claude2于2023年7月推出,拥有改进的性能,能够充当业务和技术分析师。
用例
文档分析——Claude 可用于从多个冗长的文档甚至书籍中获取见解。然后用户向Claude询问有关文档的问题。此功能来自 Claude 相当大的上下文窗口,即人工智能在生成输出之前考虑的一系列标记。Claude 的上下文窗口涵盖100,000个文本标记,即大约75,000个单词。
文本生成和摘要- 与 ChatGPT 一样,可以提示 Claude 生成问题答复或生成文本摘要。
尝试 Slack 中的Claude - https://www.anthropic.com/claude-in-slack
访问 Claude2测试版 - https://claude.ai/login
7、Stable Diffusion XL
开发商:Stability AI
https://stability.ai/
参数:基础模型:35亿个参数,模型集成管道:66亿个参数
Stable Diffusion XL是2022年声名鹊起的文本到图像模型的最新版本。在撰写本文时,0.9是最新版本,它可以生成超现实的图像。
SDXL0.9还拥有图像到图像的功能,这意味着用户可以使用一个图像作为提示来生成另一个图像。Stable Diffusion XL 还允许修复(可以填充图像中缺失或损坏的部分)和修复(可以扩展现有图像)。
用例
图像生成– 与原始Stable Diffusion相同,XL 版本可用于根据自然语言提示生成图像。然而,最新版本使用了两个模型,其中第二个模型旨在作为两阶段过程的一部分向生成的输出添加更精细的细节。
重新想象- 使用 Stability 的Clipdrop平台,Stable Diffusion XL 可用于从单个图像创建多个变体。只需单击、粘贴或上传图像即可生成更改网站插图或概念艺术图像的可能方法。
电影和电视– Stability 声称 SDXL 世代可用于电视、音乐和教学视频,以及“为设计和工业用途提供进步”。
访问Stable Diffusion XL0.9- https://huggingface.co/stabilityai/stable-diffusion-xl-base-0.9
8、Dolly
开发商:Databricks
https://www.databricks.com/
参数: Dolly:60亿个参数,Dolly2.0:120亿个参数
Databricks 的Dolly AI 模型以世界上第一个克隆哺乳动物 Dolly 羊命名,与此列表中的其他模型相比,其设计体积较小,训练成本也较低。
Dolly于3月份首次亮相,培训费用仅为30美元。它是 EleutherAI 的GPT-J语言模型的微调版本。Dolly 的设计具有高度可定制性,用户可以使用内部数据创建自己的类似 ChatGPT 的聊天机器人。
一个月后, Dolly2.0发布,并使用 EleutherAI 的 Pythia 模型系列构建。后来的迭代在 Databricks 员工众包的遵循指令的数据集上进行了微调。它专为研究和商业用途而设计。不过,Databricks 并未透露训练 Dolly2.0的成本是多少。
用例
文本生成和文档摘要——与 ChatGPT 和此列表中的其他模型一样,Dolly 的任一版本都可以在使用自然语言提示时生成文本。它相对于其他产品的优势来自于它的可定制性,企业能够使用易于访问的代码来构建自己的版本。
访问 Dolly 代码 - https://github.com/databrickslabs/dolly
访问 Dolly2.0代码 - https://huggingface.co/databricks/dolly-v2-12b
9、XGen-7B
开发商:Salesforce
https://www.salesforceairesearch.com/
参数:70亿个参数
XGen-7B是一系列大型语言模型,旨在筛选冗长的文档以提取数据见解。
Salesforce 研究人员采用了一系列70亿个参数模型,并在 Salesforce 的内部库 JaxFormer 以及公共领域教学数据上对它们进行了训练。生成的模型可以处理多达1.5万亿个token的8,000个序列长度。
用例
数据分析– 像 Meta 的 LLaMA 这样的模型的最大序列长度仅为2,000个令牌左右 – 这意味着它很难从文档等冗长的非结构化数据源中提取见解。然而,XGen-7B 可以轻松筛选冗长的文档,并在出现提示时提取见解。
代码生成– XGen-7B 模型利用Starcoder,这是由 Salesforce 和 Hugging Face 创建的代码生成模型。添加了 Starcoder 的功能以支持 XGen 的代码生成任务。
聊天机器人对话功能– 当 ChatGPT 和 Bing 的 AI 聊天等应用程序开始首次出现时,用户与应用程序对话的时间越长,底层模型就越混乱,因为它无法处理较长的上下文长度。
XGen 可能会应用于聊天机器人,以了解更长的输入可能会给企业带来巨大的好处。Salesforce 的研究人员声称,大背景“允许经过预先训练的法学硕士查看客户数据并响应有用的信息搜索查询。”
访问 XGen-7B 代码库:https://github.com/salesforce/xGen
访问 XGen-7B 模型检查点:https://huggingface.co/Salesforce/xgen-7b-8k-base
10、Vicuna
开发商:LMSYS 组织
https://lmsys.org/
参数:70亿、130亿
Vicuna是一个开源聊天机器人,也是此列表中第二个经过微调的 LLaMA 模型。为了对其进行微调,Vicuna 背后的团队使用了从ShareGPT收集的用户共享对话。
LMSYS Org 训练该模型仅花费300美元。其研究人员声称,Vicuna 的质量达到了 OpenAI ChatGPT 和 Google Bard90% 以上,同时优于 LLaMA 和斯坦福 Alpaca 等其他模型。值得注意的是,OpenAI 尚未在 GPT-4上发布任何内容,而 GPT-4现在为 ChatGPT 的一部分提供支持,因此很难确定这些发现。
用例
文本生成、辅助——与此列表中的大多数模型一样,Vicuna 可以用于生成文本,甚至可以作为虚拟助手的一种方式,用户可以使用自然语言提示机器人。
访问 Vicuna 代码 - https://huggingface.co/lmsys/vicuna-13b-delta-v1.1
11、Inflection
开发商:Inflection AI
https://inflection.ai/
参数:未知
Inflection-1是 AI 研究实验室 Inflection 开发的模型,为其虚拟助理应用程序Pi.ai提供支持。
Inflection 使用了“数千”个 Nvidia 的 H100GPU 来训练模型。该初创公司应用专有技术方法来驱动该模型,使其性能与 OpenAI 的 Chinchilla 和 PaLM-540B 等模型相当。
Inflection 使其语言模型的工作完全在内部进行,从数据摄取到模型设计。不过,该模型很快将通过 Inflection 的对话 API提供。
用例
为个人助理提供动力——Inflection-1最初是为 Pi.ai 提供动力的一种方式。据其背后的团队称,最终的应用程序旨在给人留下“善解人意、有用且安全”的印象。Inflection-1还可用于从自然语言描述生成代码并生成数学问题的答案。
12、Gorilla
开发人员:加州大学伯克利分校、微软研究院
参数:70亿个参数
Gorilla 是此列表中第一个利用 Meta 的 LLaMA 作为主体的 AI 模型,它经过了微调,以提高其进行 API 调用的能力,或者更简单地说,与外部工具配合使用的能力。端到端模型旨在为 API 调用提供服务,无需任何额外编码,并且可以与其他工具集成。
Gorilla 可以与 Apache2.0许可的 LLM 模型一起用于商业用途。
用例
虚拟助手——通过利用 API,Gorilla 可以应用于许多应用程序。例如,通过访问日历 API,Gorilla 可用于为虚拟助理应用程序提供支持。例如,该模型可以在查询时返回当前日期,而不需要任何输入。
搜索改进——在搜索选项卡中使用自然语言提示,Gorilla 可以访问以搜索为中心的 API(例如维基百科搜索),以返回短文本片段或更好地理解任务。例如,它不会列出某个名称下的所有文件,而是列出与上下文相关的最新文件。
通过 Colab 尝试 Gorilla -
https://colab.research.google.com/drive/1DEBPsccVLF_aUnmD0FwPeHFrtdC0QIUP?usp=sharing
访问 Gorilla 代码 - https://github.com/ShishirPatil/gorilla
德国软件公司SAP CEO:生成式AI有着巨大增长潜力
德国企业软件制造商SAP思爱普(SAPG.DE)的首席执行官克里斯蒂安·克莱因在《Handelsblatt》商业日报的一次采访中表示,生成式人工智能技术具有巨大的增长潜力。他表示:“目前,我们在SAP的市场规模达到5000亿美元。我们预计,通过生成式人工智能,这一潜力将显著增加。整个发展过程对于SAP来说是一个巨大的增长驱动力。”站长网2023-06-29 11:40:010002Google DeepMind 发布 CoDoC,提升医疗 AI 诊断的可靠性和准确性
据国外媒体报道,GoogleDeepMind与多个机构合作,发布了一种名为CoDoC(Complementarity-DrivenDeferraltoClinicalWorkflow)的AI系统,旨在提升医疗AI诊断的可靠性和准确性。站长网2023-07-19 19:53:480000谷歌研究团队宣布 AudioPaLM:一个能说能听的大型语言模型
大型语言模型(LLMs)近几个月一直备受关注。作为人工智能领域最重要的进展之一,这些模型正在改变人机交互的方式。随着各行各业纷纷采用这些模型,它们成为人工智能在全球蔓延的最佳例证。站长网2023-06-25 23:41:100001数据分析利器!MediaCrawler支持一键抓取小红书、抖音等平台内容
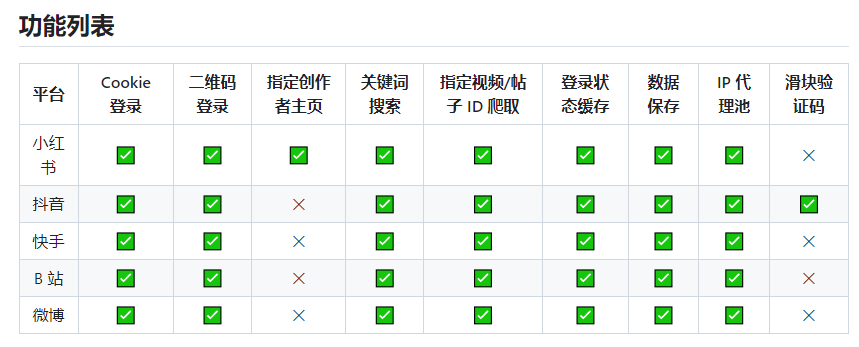
随着社交媒体的普及,越来越多的人开始使用小红书、抖音、快手、B站和微博等平台来分享自己的生活和创作。然而,有时我们可能需要将这些平台上的视频、图片、评论、点赞和转发等信息进行抓取,以便于后续的数据分析和处理。这时,我们可以借助一款名为MediaCrawler的工具来实现这一目标。项目地址:https://github.com/NanmiCoder/MediaCrawler站长网2024-03-18 22:58:270009美国参议院提交《安全人工智能法案》旨在建立违规行为数据库
参议院近日提交了一项新法案,旨在通过强制创建记录所有人工智能系统违规行为的数据库来跟踪安全问题。该法案由参议员马克·华纳(D-VA)和汤姆·蒂利斯(ThomTillis)(北卡罗来纳州)提出,名为《安全人工智能法案》。根据该法案,将在国家安全局建立人工智能安全中心,领导“反人工智能”研究并制定防止反人工智能措施的指南。0000