650亿参数大模型预训练方案开源可商用!LLaMA训练加速38%,来自明星开源项目
650亿参数大模型的预训练方案,发布即开源。
训练速度较传统方案提升38%。
这就是由Colossal-AI最新发布的类LLaMA基础大模型预训练方案。要知道,在“百模大战”背景下,谁拥有自家大模型,往往被视为核心竞争力。
在这个节点下,愿意开源大模型的公司少之又少。
但自己从头训练一个大模型,对技术、资金都有很高要求。
由此,Colossal-AI最新的开源动作,可以说是应时势所需了。
并且它还不限制商业使用,开箱即用仅需4步。
具体项目有哪些内容?一起往下看~
开源地址:https://github.com/hpcaitech/ColossalAI
32张A100/A800即可使用
实际上,自从Meta开源LLaMA后,掀起了一波微调项目热潮,如Alpaca、Vicuna、ColossalChat等都是在其基础上打造的。

但是LLaMA只开源了模型权重且限制商业使用,微调能够提升和注入的知识与能力也相对有限。
对于真正想要投身大模型浪潮的企业来说,训练自己的核心大模型非常重要。
开源社区也此前已献了一系列工作:
RedPajama:开源可商用类LLaMA数据集(无训练代码和模型)
OpenLLaMA:开源可商用类LLaMA7B/13B模型,使用EasyLM基于JAX和TPU训练
Falcon:开源可商用类LLaMA7B/40B模型(无训练代码)
但这些都还不够,因为对于最主流的PyTorch GPU生态,仍缺乏高效、可靠、易用的类LLaMA基础大模型预训练方案。
所以Colossal-AI交出了最新的开源答卷。
仅需32张A100/A800,即可搞定650亿参数类LLaMA大模型预训练,训练速度提升38%。

而像原生PyTorch、FSDP等,则因显存溢出无法运行该任务。
Hugging Face accelerate、DeepSpeed、Megatron-LM也未对LLaMA预训练进行官方支持。
开箱即用、4步搞定
而这一项目真正上手起来也很简易。共有四步:
1、安装Colossal-AI
2、安装其他依赖项
3、数据集
4、运行命令
具体代码如下:
第一步、安装Colossal-AI。
gitclone-bexample/llamahttps://github.com/hpcaitech/ColossalAI.git
cdColossalAI
#installandenableCUDAkernelfusion
CUDA_EXT=1pipinstall.
第二步、安装其他依赖项。
cdexamples/language/llama
#installotherdependencies
pipinstall-rrequirements.txt
#useflashattention
pipinstallxformers
第三步、数据集。
默认数据集togethercomputer/RedPajama-Data-1T-Sample将在首次运行时自动下载,也可通过-d或—dataset指定自定义数据集。
第四步、运行命令。
已提供7B和65B的测速脚本,仅需根据实际硬件环境设置所用多节点的host name即可运行性能测试。
cdbenchmark_65B/gemini_auto
bashbatch12_seq2048_flash_attn.sh
对于实际的预训练任务,使用与速度测试一致,启动相应命令即可,如使用4节点*8卡训练65B的模型。
colossalairun--nproc_per_node8--hostfileYOUR_HOST_FILE--master_addrYOUR_MASTER_ADDRpretrain.py-c'65b'--plugin"gemini"-l2048-g-b8-a
如果使用Colossal-AI gemini_auto并行策略,可便捷实现多机多卡并行训练,降低显存消耗的同时保持高速训练。
还可根据硬件环境或实际需求,选择流水并行 张量并行 ZeRO1等复杂并行策略组合。
其中,通过Colossal-AI的Booster Plugins,用户可以便捷自定义并行训练,如选择Low Level ZeRO、Gemini、DDP等并行策略。
Gradient checkpointing通过在反向传播时重新计算模型的activation来减少内存使用。
通过引入Flash attention机制加速计算并节省显存。用户可以通过命令行参数便捷控制数十个类似的自定义参数,在保持高性能的同时为自定义开发保持了灵活性。
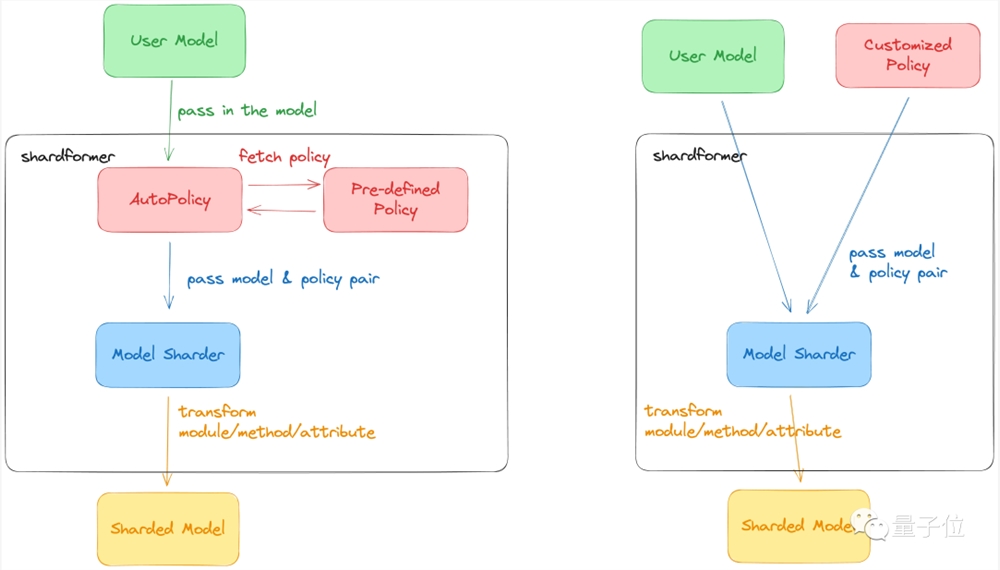
Colossal-AI最新的ShardFormer极大降低了使用多维并行训练LLM的上手成本。
现已支持包括LLaMA的多种等主流模型,且原生支持Huggingface/transformers模型库。
无需改造模型,即可支持多维并行(流水、张量、ZeRO、DDP等)的各种配置组合,能够在各种硬件配置上都发挥卓越的性能。
Colossal-AI:大模型系统基础设施
带来如上新工作的Colossal-AI,如今已是大模型趋势下的明星开发工具和社区了。
Colossal-AI上述解决方案已在某世界500强落地应用,在千卡集群性能优异,仅需数周即可完成千亿参数私有大模型预训练。
上海AI Lab与商汤等新近发布的InternLM也基于Colossal-AI在千卡实现高效预训练。
自开源以来,Colossal-AI多次在GitHub热榜位列世界第一,获得 GitHub Star超3万颗,并成功入选SC、AAAI、PPoPP、CVPR、ISC等国际 AI 与HPC顶级会议的官方教程,已有上百家企业参与共建Colossal-AI生态。

它由加州伯克利大学杰出教授 James Demmel 和新加坡国立大学校长青年教授尤洋领导开发。
Colossal-AI基于PyTorch,可通过高效多维并行、异构内存等,主打为AI大模型训练/微调/推理的开发与应用成本,降低GPU需求等。
其背后公司潞晨科技,近期获得数亿元A轮融资,已在成立18个月内已迅速连续完成三轮融资。
开源地址:https://github.com/hpcaitech/ColossalAI
参考链接:https://www.hpc-ai.tech/blog/large-model-pretraining
—完—
B站宣布微短剧扶持计划 内容涵盖广泛题材
在上海电视节的微短剧大会上,B站发布了精品微短剧领域的内容规划和扶持计划。B站计划在今年推出近20部优质的精品微短剧作品,涵盖社会、文化、校园、悬疑、喜剧、文旅、历史和现实主义等多种题材。站长网2024-06-26 16:03:420000SK 海力士称内存芯片复苏已经开始 人工智能需求强劲
韩国SK海力士周三表示,由于人工智能需求强劲,内存芯片市场正在从严重低迷中复苏,尽管其报告显示第二季度运营亏损。特别是企业买家和游戏个人电脑对内存芯片的需求预计将在今年下半年比上半年增加,这家全球第二大内存芯片制造商在一份声明中表示。站长网2023-07-26 11:20:480000马斯克宣布将卸任推特CEO 转向产品和技术工作
埃隆·马斯克周四表示,推特将迎来一位新的首席执行官,他本人将转向产品和技术方面的工作。马斯克通过推特表示,这位新的首席执行官是一位未透露姓名的女性,将在大约六周后上任。他补充说,他将“转变为执行主席兼首席技术官,负责产品、软件和系统运营。”特斯拉股价当晚涨了2%以上,显示出投资者对这一举动感到满意。站长网2023-05-12 09:19:260000即日起,1688支持七天无理由退货
CEO余涌:现在我重点抓的是用户体验和用户履约。1688调整七天无理由退货服务批发平台也能七天无理由退货?日前,1688调整了《商品七日无理由退货服务相关规则》,已于2月2日正式生效。此次规则变更,主要是结合商品要求以及卖家对商品起批量和现货档/定制档的设置,对七天无理由退货服务的适用情形和相关规则进行了明确和调整。站长网2024-02-05 09:30:350000Semafor记者将利用人工智能来策划新闻
Semafor希望通过让记者使用定制的人工智能搜索工具来策划更多新闻,使其主页更有价值。Semafor编辑BenSmith于2023年4月10日在纽约市举行了Semafor媒体峰会上的发表演讲。在网络上构建新闻产品再次成为热潮,随着社交流量下降和搜索引擎调整,出版商们开始重新关注他们的网站作为目的地。站长网2024-02-06 09:36:250000