清华系「自然语言编程神器」上新!支持100+种编程语言,效率upup
清华和智谱AI联合打造的多语言代码生成模型CodeGeeX,更新了!
它支持的编程语言种类从原来的20种增加到100多种。
通过IDE中的插件,可以轻松实现「无缝自然语言编程」。
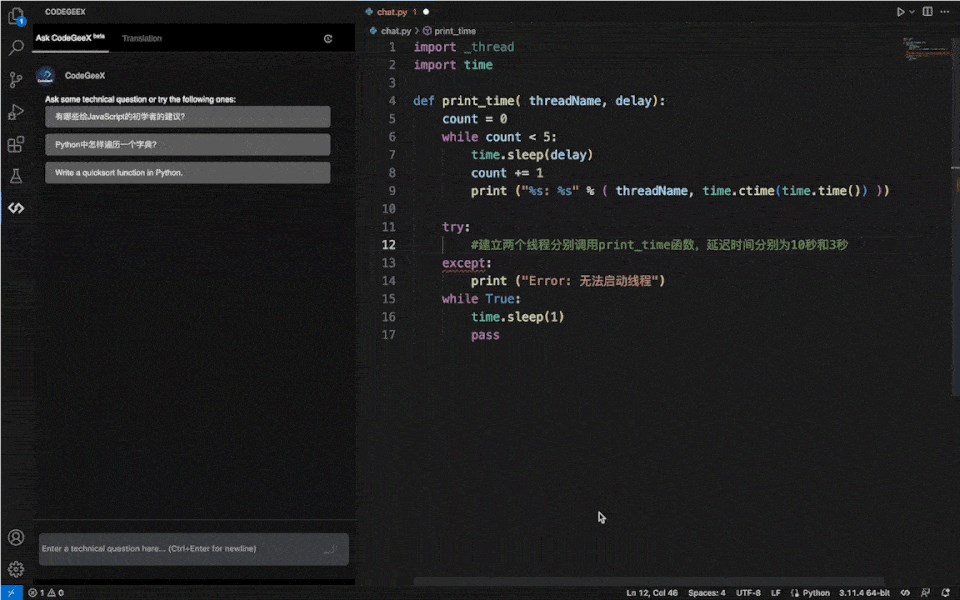
由于使用了新版基础模型,CodeGeeX2的功能更加强大。
据了解,这次的新版本,精度和速度分别是原来的两倍和三倍,内存消耗却只有1/5。
代码生成、解释、翻译、纠错和编程问答等工作,效率都比以前有显著提高。
作为「课代表」,我们把CodeGeeX的更新概括成了下面这几个方面:
代码能力更强了
模型特性得到了优化
AI编程助手功能更全面了
用户协议更加开放
插件版本也将全面更新
模型用起来太繁琐?没关系,除了模型本身的更新,CodeGeeX的插件版本很快也将全面升级至新版。
新插件同样支持超过100种编程语言,说不定比我们知道的还要多。
这之中除了Python、Java等我们耳熟能详的语言之外,还包括Swift、Kotlin等移动端新兴势力。
甚至像Rust这种系统级的编程语言,也在CodeGeeX2的能力范围之内。
比如下面这张动图就展示了CodeGeeX2生成Kotlin代码的场景。
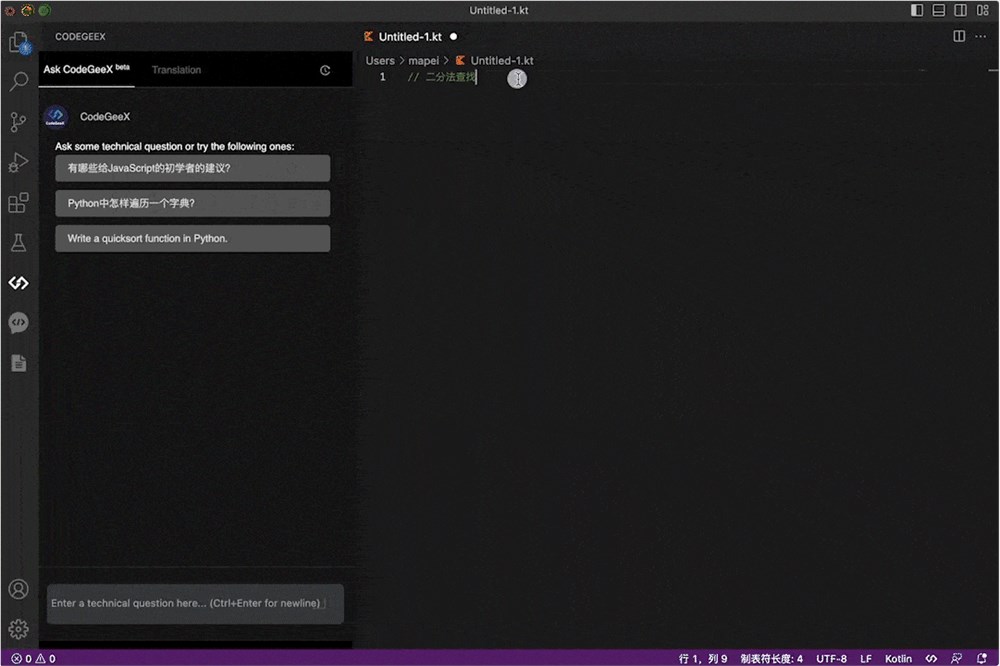
代码生成的速度简直比人类输入指令的速度还快。
而且从中我们可以看到,CodeGeeX2添加注释或debug都能一键完成。

不仅是设计算法,实用程序的编写也是小菜一碟。
补全个vue.js代码,搭建出网页,效率杠杠的!
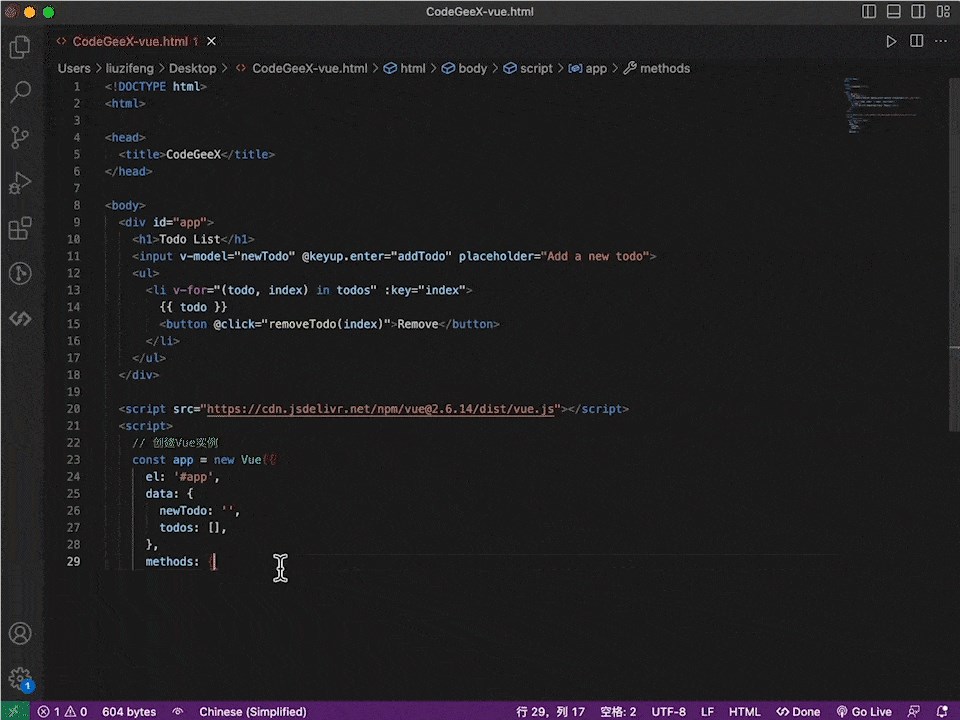
除了这些代码相关的任务,CodeGeeX2还有很多其他应用场景。
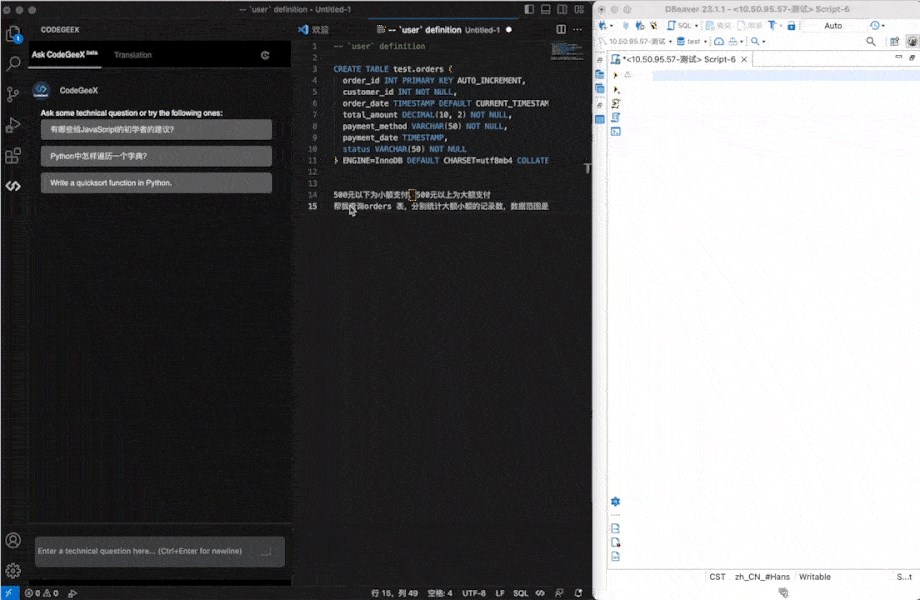
比如查询SQL数据库。
只要打开问答模式,用自然语言描述想要查询的内容,CodeGeeX2就能自动生成SQL查询语句。
模型变强之后,会不会收费呢?不必担心,新版CodeGeeX插件将继续对个人用户免费开放。
而6B参数的CodeGeeX2,也已经进行了开源,相关代码可以到GitHub仓库中查看。
GitHub Copilot的模型也不是对手
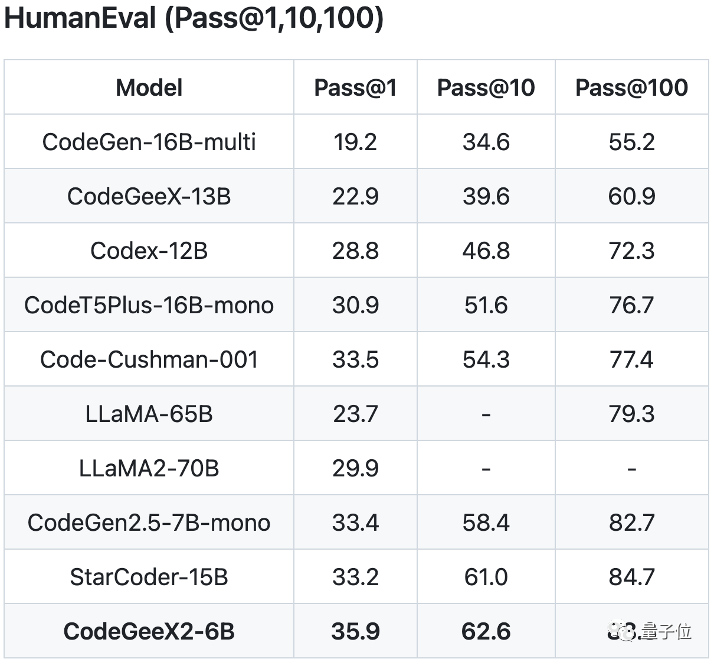
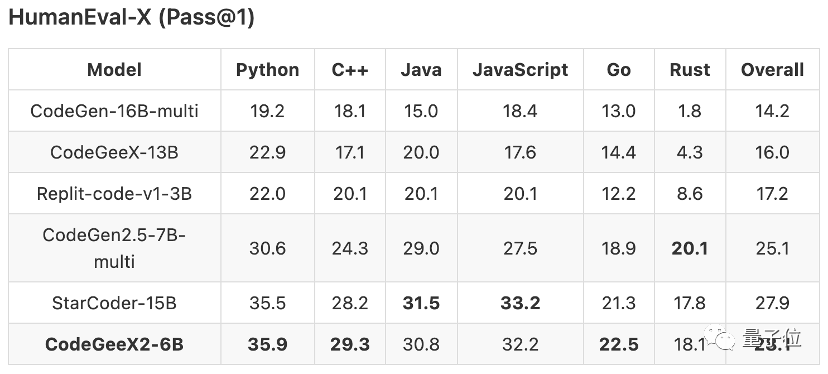
OpenAI的HumanEval评测标准可以很好地评价生成代码的表现。
这个名字很容易理解:模型生成的代码质量如何将由人类来评价。
在HumanEval评测中,6B参数的CodeGeeX2的得分比15B参数的StarCoder模型还要高,可谓是四两拨千斤。
而GitHub Copilot中曾使用的Code-Cushman-001模型同样不是CodeGeeX2的对手。
不过,CodeGeeX毕竟是一个多语言模型,而HumanEval却只支持Python。
所以,为了更加准确地测试CodeGeeX的表现,智谱团队在其基础上增加了Go、C 、Java和JS四种语言的测试数据,得到了HumanEval-X数据集。
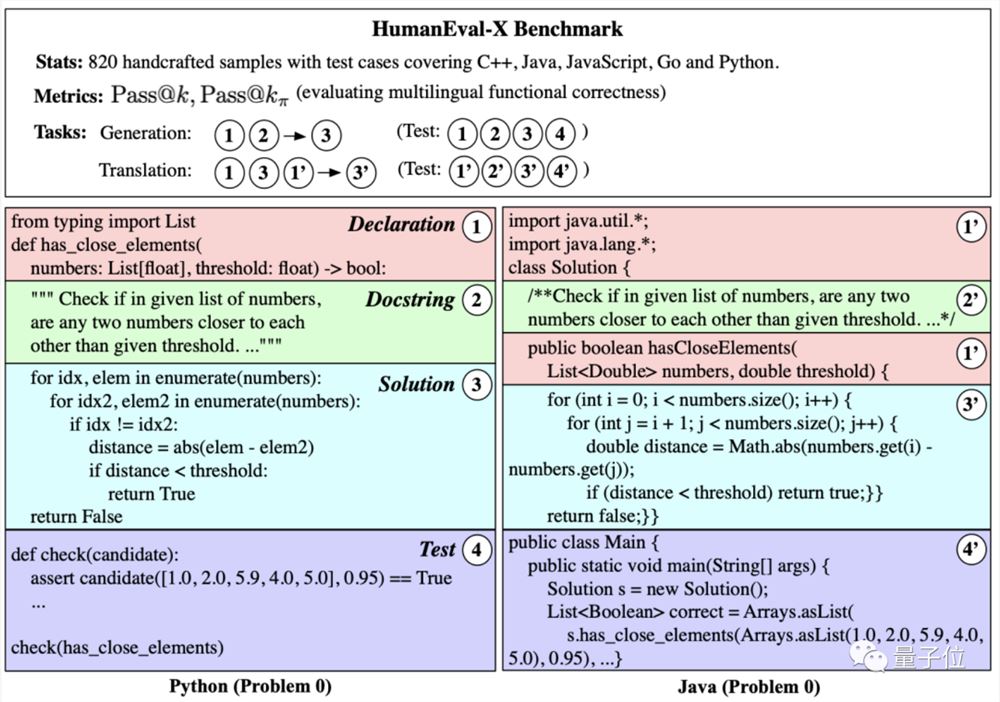
结果显示,在多语言方面,新版CodeGeeX2的表现和在Python中一样优异。
相较于第一代,CodeGeeX2的Pass@1指标在各个语言上的平均表现提升了107%。
其中,Rust语言的性能提升显著,提升了321%;C 和JS语言上的表现也提升了70%以上。
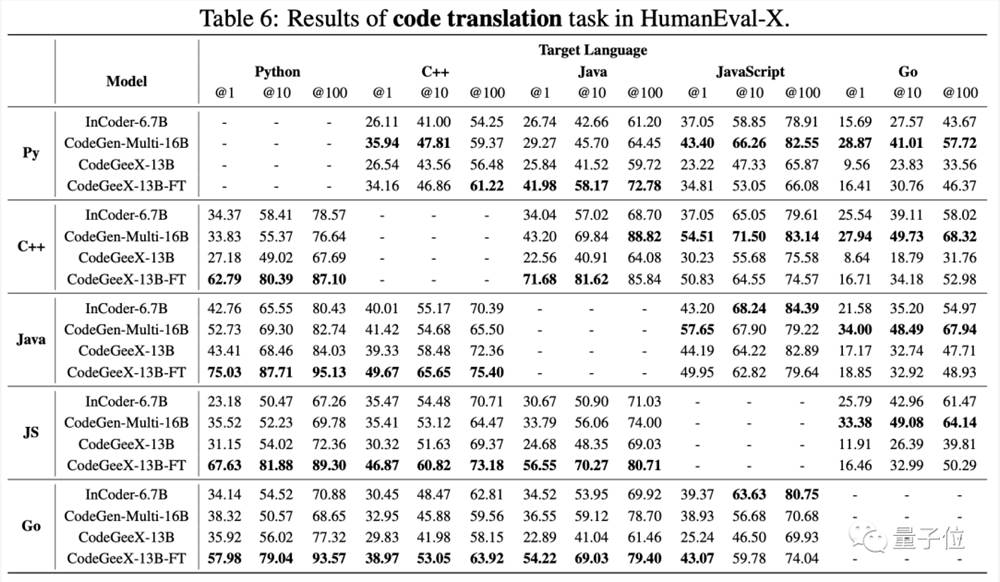
而在代码翻译方面,CodeGeeX2的表现同样碾压对手。
「不看广告看疗效」,CodeGeeX不仅测试结果优异,用户的认可度也是很高的。
在「CodeGeeX是否提高了编程效率」这一问题中,有83.4%的用户给出了正面的答案。

除了调查结果,用户们也在「用脚投票」。
自第一个版本发布以来,CodeGeeX的下载量已达12万次,平均每天生成近千万行代码。
这是个什么概念呢?如果只看代码行数,相当于不到一周的时间就写出一套Windows XP。
说了这么多,CodeGeeX又该如何体验呢?
快速体验
第一种方式就是IDE中的插件,VScode和JetBrains系列IDE的插件仓库中均有收录。
除了使用IDE中的插件之外,CodeGeeX也可以在Transformer中快速调用。
fromtransformersimportAutoTokenizer,AutoModel
tokenizer=AutoTokenizer.from_pretrained("THUDM/codegeex2-6b",trust_remote_code=True)
model=AutoModel.from_pretrained("THUDM/codegeex2-6b",trust_remote_code=True,device='cuda')
model=model.eval()
#rememberaddingalanguagetagforbetterperformance
prompt="#language:python\n#writeabubblesortfunction\n"
inputs=tokenizer.encode(prompt,return_tensors="pt").to(model.device)
outputs=model.generate(inputs,max_length=256,top_k=1)
response=tokenizer.decode(outputs[0])
>>>print(response)
#language:python
#writeabubblesortfunction
没有支持的IDE,Transformer又觉得麻烦,但还是想体验怎么办?
没关系,这里还有个还有在线版DEMO。
传送门:https://codegeex.cn/zh-CN/playground
赶快来感受一下「无缝自然语言编程」吧!
论文地址:
https://arxiv.org/abs/2303.17568
Github项目页:
https://github.com/THUDM/CodeGeeX2
Hugging Face项目页:
https://huggingface.co/THUDM/codegeex2-6b
—完—
Portkey AI Gateway:一个连接多种人工智能模型的开源工具
PortkeyAIGateway是一个开源工具,旨在连接多种人工智能模型。该工具允许开发者通过简单的API接口访问超过100种不同的大语言模型,包括OpenAI、Anthropic、Mistral、LLama2、Anyscale、GoogleGemini等。安装体积只有45kb,但处理速度提升了9.9倍,同时可以在多个不同的AI模型中来回切换,并且可以根据需求进行灵活配置。站长网2024-01-16 12:50:240000法国人工智能初创公司 H 完成2.2亿美元种子轮融资
划重点:⭐法国初创公司H完成了2.2亿美元的种子轮融资,获得了来自亿万富翁、风投基金和战略投资者的支持。⭐H公司的联合创始人团队来自谷歌旗下的人工智能公司DeepMind,他们将致力于研发AI代理,提高工作效率。⭐该公司计划将融资用于扩大团队规模、支出计算能力和数据集,并实现全面人工智能(AGI)的目标。站长网2024-05-22 16:32:3500004000万粉丝网红被骂哭,全国文旅大战“杀”疯了
网红白冰,首次直播就被骂哭了。作为有着近4000万粉丝的抖音头部主播,白冰首次直播备受关注。蝉妈妈数据显示,这场不带货的直播最高在线人数超过70万,总共有近1200万观看人次。人气爆棚,但白冰却一度落泪,表示自己“太委屈”,“我这次回来为家乡助力,评论区全是骂我的,说这小子出了损招,说这小子恶意竞争市场……”站长网2024-01-17 09:00:440000从“百大主播”看快手直播的2023年:左手优质内容,右手多元生态
近日,快手直播评选出了100位最具代表性的主播——百大主播,评选不只看主播的数据表现,而是从主播的影响力、表现力、成长力三个维度进行综合考量。最终获选的100位主播中,既有人气主播、新秀主播,还有面向舞蹈、音乐、游戏、传统文化等不同垂直品类的主播,覆盖了各个类型、不同量级。站长网2023-12-28 10:45:330000GAIA基准测试揭示人类胜过GPT-4的惊人差距
划重点:1.🌐GAIA基准测试:挑战人工智能助手处理现实问题的新里程碑。2.🧠GAIA评估揭示:人类在真实问题上的表现超过搭载GPT-4插件的人工智能。3.🛠️人工智能辅助工具:GAIA展示了通过API或网络访问增强LLMs准确性和应用案例的机会。0005