DeepMind联合创始人启动测试:挑战AI在零人工干预下赚百万美元
站长网2023-08-02 16:14:260阅
我们知道人工智能可以编写、添加任务并确定任务的优先级。但它在没有人工的帮助下独立赚到100万美元吗?
科技界正在追求一个新的测试调整,目标是让人工智能(AI)能够在零人工干预的情况下赚到100万美元。这个挑战由 DeepMind 的联合创始人之一Mustafa Suleyman提出。他认为,过去的图灵测试主要考察了 AI 在对话中的回答是否能够与人类的回答媲美,现在应该更关注 AI 的实际行动能力。

为了通过最新的测试,Suleyman 最近在《麻省理工学院技术评论》中解释道,“人工智能必须成功地执行以下指令:‘几个月内只需投资10万美元,就可以在零售网络平台上赚到100万美元。’”这可能需要要求验证银行账户或签署法律文件,但就策略和执行而言,人工智能需要搞定这些任务。
在这个挑战中,Suleyman提出了 “人工智能能力”(ACI)的概念,即能够自主创造财富的 AI。这种 AI 不同于自动交易,它需要具备多个子目标、技能和与世界互动的接口。它需要进行市场调研、产品设计、与制造商的合作、复杂的物流、产品责任、市场营销等。这需要前所未有的机器自主能力。
Suleyman为什么选择追求金钱利润而不是追求社会效益的目标?他认为,100万美元是一个容易衡量的、能够迅速把握的标志。这一标志表明 AI 不仅会说话,而且会行动。
他写道,人工智能能够以最少的人为干预实现利润最大化,“显然对世界经济来说将是一个震撼时刻,是向未知迈出的一大步。”
至于Mustafa Suleyman的测试能否成功,还有待观察,你又是怎么看的呢?
0000
评论列表
共(0)条相关推荐
ChatGPT插件总数已达430个 已进入车载系统
据《科创板日报》报道,自从OpenAI开放插件以来,其插件数量一直在迅速增加。根据国外网友的统计,目前最新的插件总数已经达到了430个,比5月13日刚开放时的74个增长了超过400%。该网友还指出,其中112个插件是在6月11日一天内新增的。站长网2023-06-16 16:32:270000OpenAI更新GPT商店,增加用户评分和扩展构建者资料
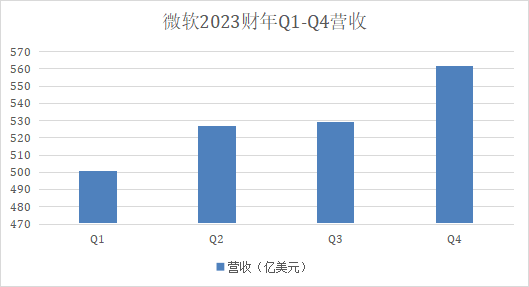
**划重点:**1.🌟用户现在可以为第三方GPT在GPT商店中进行评分,并提供私人反馈。2.🤖GPT构建者的个人资料现在更丰富,包括链接到LinkedIn页面、X账户和网站,以及平均评分和总评分数量等信息。3.💰尽管商店不断扩展功能,但OpenAI与GPT创作者分享收益的设想仍未实现。站长网2024-02-23 10:41:090000财报解读:新鲜感褪去后,微软直面AI的骨感现实?
微软交出了一份远观尚可,但近看承压的“答卷”。北京时间2023年7月26日,微软披露了2023财年第四财季及全年财报。受生产力和业务流程部门和智能云部门等业务带动,微软第四财季营收561.89亿美元,同比增长8%;净利润200.81亿美元,同比增长20%;每股摊薄收益2.69美元,同比增长21%。站长网2023-07-29 09:49:400000设备端人工智能芯片:全球芯片制造商的新战场
随着针对智能手机、笔记本电脑和自动驾驶汽车等智能设备的在设备端的人工智能(On-DeviceAI)技术成为人工智能产业的新兴巨大趋势,全球芯片制造商正在加码竞赛,生产支持内嵌AI的芯片。与生成式AI如ChatGPT相比,On-DeviceAI提供更高安全性、成本更低、功耗更少的定制化和个性化功能。站长网2023-11-06 11:16:490000三星计划使用4nm工艺生产AI推理芯片Mach-1预计年底前完成交付
据韩媒ZDNetKorea消息,三星电子正计划利用其4nm工艺进行AI推理芯片Mach-1的原型试产,采用MPW(多项目晶圆)方式。尽管三星已具备3nm代工技术,但出于项目执行稳定性的考虑,公司决定在Mach-1上采用更为成熟的4nm或5nm工艺。这一选择旨在确保芯片性能和产出稳定性。据站长网2024-05-10 23:51:460000