你有没深入想过,什么造成了GPT-4的输出很随机?
Google Deepmind 可能早就意识到了这个问题。
今年,大型语言模型(LLM)成为 AI 领域最受关注的焦点,OpenAI 的 ChatGPT 和 GPT-4更是爆火出圈。GPT-4在自然语言理解与生成、逻辑推理、代码生成等方面性能出色,令人惊艳。
然而,人们逐渐发现 GPT-4的生成结果具有较大的不确定性。对于用户输入的问题,GPT-4给出的回答往往是随机的。
我们知道,大模型中有一个 temperature 参数,用于控制生成结果的多样性和随机性。temperature 设置为0意味着贪婪采样(greedy sampling),模型的生成结果应该是确定的,而 GPT-4即使在 temperature=0.0时,生成的结果依然是随机的。
在一场圆桌开发者会议上,有人曾直接向 OpenAI 的技术人员询问过这个问题,得到的回答是这样的:「老实说,我们也很困惑。我们认为系统中可能存在一些错误,或者优化的浮点计算中存在一些不确定性......」
值得注意的是,早在2021年就有网友针对 OpenAI Codex 提出过这个疑问。这意味着这种随机性可能有更深层次的原因。
图源:https://community.openai.com/t/a-question-on-determinism/8185
现在,一位名为 Sherman Chann 的开发者在个人博客中详细分析了这个问题,并表示:「GPT-4生成结果的不确定性是由稀疏 MoE 引起的」。
Sherman Chann 博客地址:https://152334h.github.io/blog/non-determinism-in-gpt-4/
Sherman Chann 这篇博客受到了 Google DeepMind 最近一篇关于 Soft MoE 的论文《From Sparse to Soft Mixtures of Experts》启发。

论文地址:https://arxiv.org/pdf/2308.00951.pdf
在 Soft MoE 论文的2.2节中,有这样一段描述:
在容量限制下,所有稀疏 MoE 都以固定大小的组来路由 token,并强制(或鼓励)组内平衡。当组内包含来自不同序列或输入的 token 时,这些 token 通常会相互竞争专家缓冲区中的可用位置。因此,模型在序列级别不再具有确定性,而仅在批次级别(batch-level)具有确定性,因为某些输入序列可能会影响其他输入的最终预测。

此前,有人称 GPT-4是一个混合专家模型(MoE)。Sherman Chann 基于此做出了一个假设:
GPT-4API 用执行批推理(batch inference)的后端来托管。尽管一些随机性可能是因为其他因素,但 API 中的绝大多数不确定性是由于其稀疏 MoE 架构未能强制执行每个序列的确定性。
也就是说,Sherman Chann 假设:「稀疏 MoE 模型中的批推理是 GPT-4API 中大多数不确定性的根本原因」。为了验证这个假设,Sherman Chann 用 GPT-4编写了一个代码脚本:
importosimportjsonimporttqdmimportopenaifromtimeimportsleepfrompathlibimportPathchat_models=["gpt-4","gpt-3.5-turbo"]message_history=[{"role":"system","content":"Youareahelpfulassistant."},{"role":"user","content":"Writeaunique,surprising,extremelyrandomizedstorywithhighlyunpredictablechangesofevents."}]completion_models=["text-davinci-003","text-davinci-001","davinci-instruct-beta","davinci"]prompt="[System:Youareahelpfulassistant]\n\nUser:Writeaunique,surprising,extremelyrandomizedstorywithhighlyunpredictablechangesofevents.\n\nAI:"results=[]importtimeclassTimeIt:def__init__(self,name):self.name=namedef__enter__(self):self.start=time.time()def__exit__(self,*args):print(f"{self.name}took{time.time()-self.start}seconds")C=30#numberofcompletionstomakepermodelN=128#max_tokens#Testingchatmodelsformodelinchat_models:sequences=set()errors=0#althoughItrackerrors,atnopointwereanyerrorseveremittedwithTimeIt(model):for_inrange(C):try:completion=openai.ChatCompletion.create(model=model,messages=message_history,max_tokens=N,temperature=0,logit_bias={"100257":-100.0},#thisdoesn'treallydoanything,becausechatmodelsdon'tdo<|endoftext|>much)sequences.add(completion.choices[0].message['content'])sleep(1)#cheaplyavoidratelimitingexceptExceptionase:print('somethingwentwrongfor',model,e)errors =1print(f"\nModel{model}created{len(sequences)}({errors=})uniquesequences:")print(json.dumps(list(sequences)))results.append((len(sequences),model))#Testingcompletionmodelsformodelincompletion_models:sequences=set()errors=0withTimeIt(model):for_inrange(C):try:completion=openai.Completion.create(model=model,prompt=prompt,max_tokens=N,temperature=0,logit_bias={"50256":-100.0},#preventEOS)sequences.add(completion.choices[0].text)sleep(1)exceptExceptionase:print('somethingwentwrongfor',model,e)errors =1print(f"\nModel{model}created{len(sequences)}({errors=})uniquesequences:")print(json.dumps(list(sequences)))results.append((len(sequences),model))#Printingtableofresultsprint("\nTableofResults:")print("Num_Sequences\tModel_Name")fornum_sequences,model_nameinresults:print(f"{num_sequences}\t{model_name}")
当 N=30,max_tokens=128时,结果如下表所示:
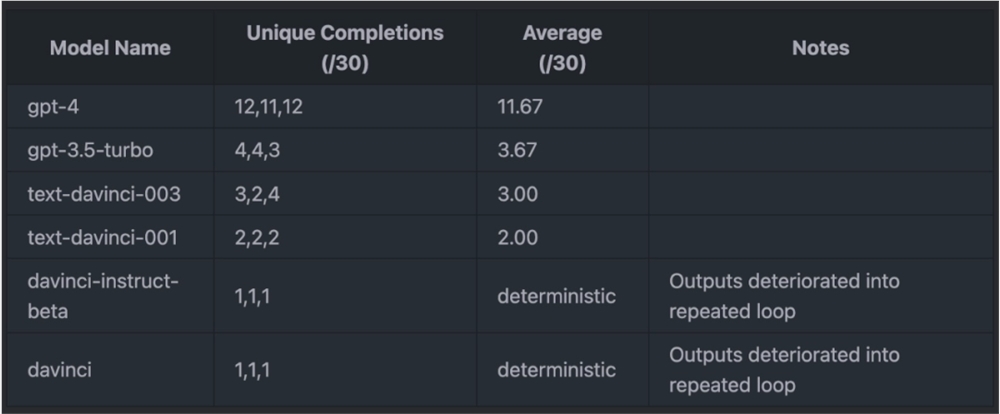
在 Sherman Chann 注意到 logit_bias 问题之前,还得到了如下结果(max_tokens=256):
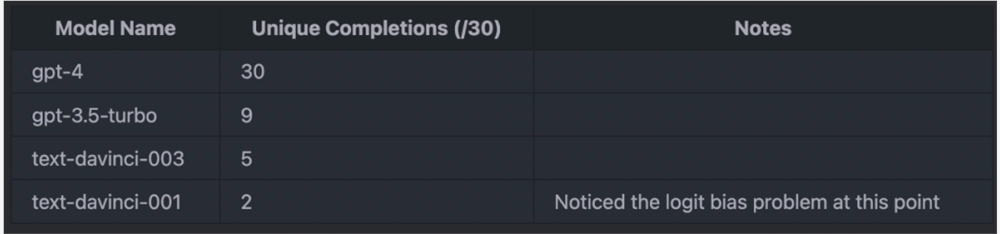
实验结果表明,GPT-4的输出总是不确定的(unique completion 数值很高,表明对于相同的输入,GPT-4生成的输出总是不同的),这几乎可以证实 GPT-4存在问题。并且,所有其他不会陷入重复无用循环的模型也存在某种程度的不确定性。这似乎说明不可靠的 GPU 计算也会造成一定程度的随机性。
Sherman Chann 表示:「如果不确定性是稀疏 MoE 批推理固有的特征,那么这一事实对于任何使用该类模型的研究来说都应该是显而易见的。Google Deepmind 的研究团队显然知道这一点,并且他们认为这个问题很微不足道,以至于只是把它写成了一句不经意的话放在论文中」。
此外,Sherman Chann 还推测 GPT-3.5-Turbo 可能也使用了 MoE。
网友怎么看
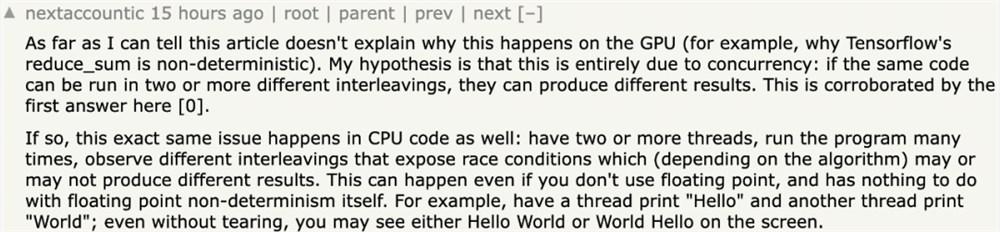
这篇博客发表后,开发者们也开始讨论 GPT-4输出的不确定问题。有人认为这可能是「多线程并行」造成的:
也有人表示:「虽然计算是确定的,但是执行计算的多个处理器之间可能存在时钟频率偏差」:

一位支持 Sherman Chann 的假设的开发者说道:「GPT-3.5-Turbo 可能就是 OpenAI 为 GPT-4构建的小型测试模型」。

还有开发者分析道:「按照 Soft MoE 论文的说法,稀疏 MoE 不仅引入了不确定性,还可能会使模型的响应质量取决于有多少并发请求正在争夺专家模块的分配」。

对此,你怎么看?
参考链接:
https://news.ycombinator.com/item?id=37006224
小红书引流规则又变了?客资商家该如何应对
小红书商家们,你们这几天有没有收到这条信息?1月7日开始,【私信获客工具】是小红书引流、和用户私信沟通交换联系方式的唯一合规路径。除此之外所有引流方式都会违规,包括在对话框内以文字形式发送联系方式(联系电话、微信号),违规会被禁言,严重的还会导致封号,近期平台已经针对部分账号进行处罚。【私信获客工具】到底是什么?小红书商家又该如何应对这次变化?一起往下看看吧。01.私信获客工具是什么?0000Steam上架“重庆本地麻辣捆绑包”:内含三款游戏 共计230.4元
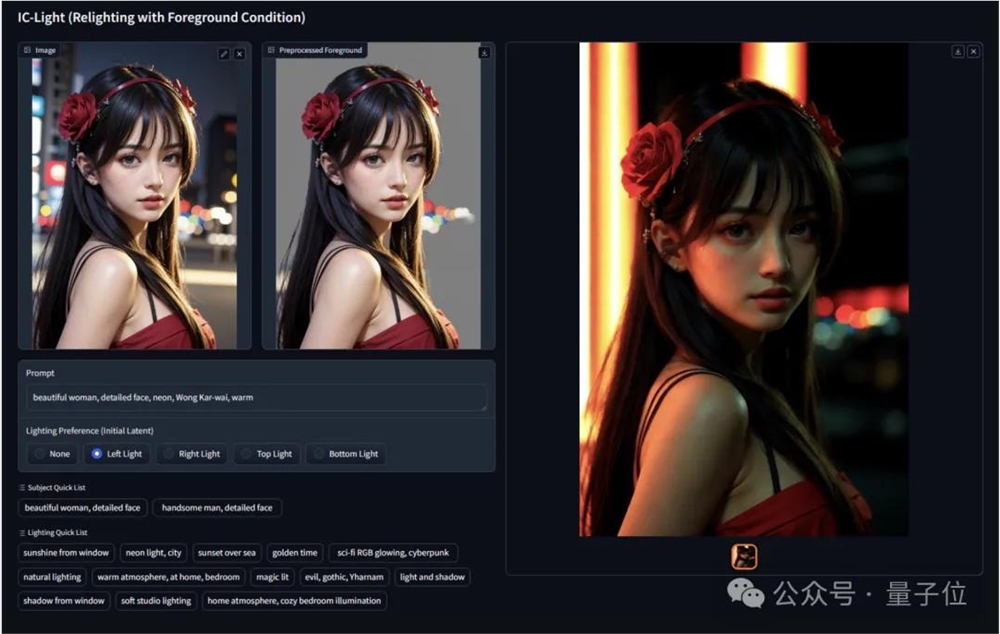
快科技1月23日消息,Steam推出重庆本地麻辣捆绑包”,内含《沙石镇时光》《戴森球计划》《了不起的修仙模拟器》三款游戏。原价256元,打包直降10%,售价230.4元。官方介绍称,三支来自重庆的团队想搞一点又麻又辣的火锅搭配,给五湖四海的朋友们尝尝鲜”。《沙石镇时光》站长网2025-01-23 20:11:200000ControlNet作者新作爆火:P照片换背景不求人,AI打光完美融入
ControlNet作者新作,玩儿得人直呼过瘾,刚开源就揽星1.2k。用于操纵图像照明效果的IC-Light,全称lmposingConsistentLight。玩法很简单:上传任意一张图,系统会自动分离人物等主体,选择光源位置,填上提示词,就能毫无破绽的融入新环境了!赶紧来个王家卫式的打光:不喜欢?没关系,换成窗外打进来的自然光,也就分分钟的事。站长网2024-05-11 20:30:240000谷歌最新的人工智能大型语言模型 PaLM 2 在训练中使用的文本数据是其前身的近五倍
据CNBC披露,谷歌上周宣布的新型大型语言模型PaLM2使用的训练数据量几乎是2022年前身的5倍,可执行更高级的编码、数学和创意写作任务。据CNBC获悉,谷歌的新通用大型语言模型(LLM)PaLM2已训练了3.6万亿个token。而token是单词字符串,是训练LLM的重要组成,因为它们使模型能够预测序列中接下来出现的单词。站长网2023-05-18 09:29:380000OpenAI CEO 访韩 或就 AI 芯片合作事宜与 SK 集团会长会面
随着企业和消费者对人工智能(AI)应用的兴趣日益浓厚,对AI芯片的需求也在快速增长。为应对可能的芯片短缺,美国AI初创公司OpenAI正在寻求解决方案。据报道,OpenAI计划成立一家芯片制造公司。OpenAICEO萨姆・阿尔特曼本周访问韩国首尔,据推测他将与SK集团会长崔泰源就AI芯片合作进行商谈。阿尔特曼此行还可能与三星电子就代工和存储器方面的合作进行洽谈。站长网2024-01-22 09:27:450000