羊驼进化成鲸鱼,Meta把对齐「自动化」,Humpback击败现有全部LLaMa模型
数据质量很重要。
这一年来,以 ChatGPT 和 GPT-4为代表的大语言模型(LLM)发展迅速,紧随其后,Meta 开源的 LLaMa、Llama2系列模型在 AI 界也引起的了不小的轰动。但随之而来的是争议不断,有人认为 LLM 存在一些不可控的风险,给人类生存构成一些潜在威胁。
为了应对这些挑战,对 LLM 对齐的研究变得越来越重要,有研究者提出指令跟随(instruction following),但这种方法需要大量的人工注释。然而,注释如此高质量的指令跟随数据集耗费巨大。
本文来自Meta AI 的研究者提出了一种可扩展的方法即指令回译(instruction backtranslation),该方法通过自动注释相应的指令来构建高质量的指令跟随语言模型。

论文地址:https://arxiv.org/pdf/2308.06259.pdf
具体而言,该研究从一个语言模型开始,并作为种子模型,该模型在少量的种子数据以及 web 语料库上进行了微调。种子模型的作用是用来构建训练样本,然后这些样本中的一些高质量样本将会被筛选出来,接着,这些数据被用来微调一个更强大的模型。
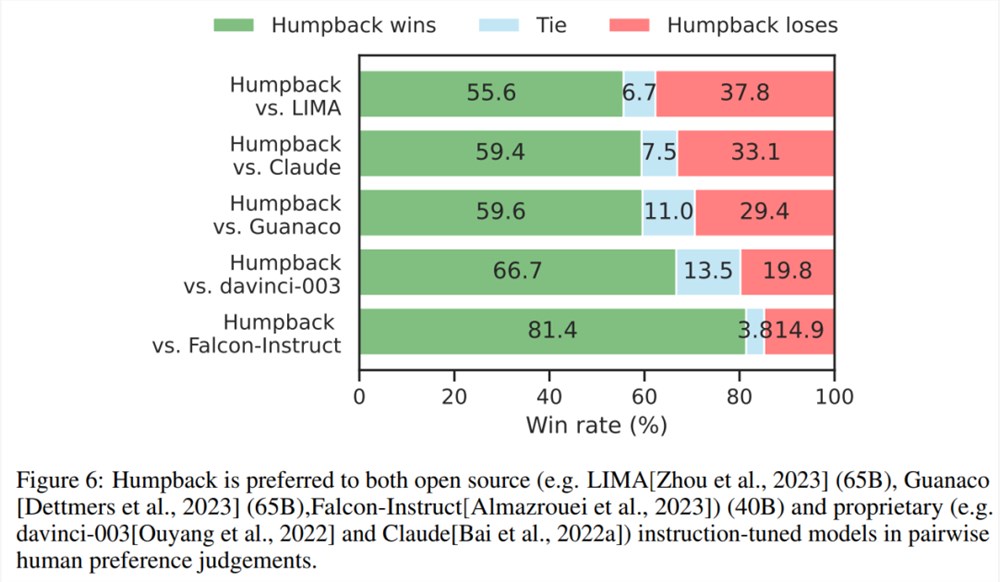
经过两轮迭代的数据集对 LLaMa 进行微调,所产生的模型 Humpback 在 Alpaca 排行榜上优于其他现有的非蒸馏模型,如 LIMA、Claude、Guanaco 等。
Humpback 原意为座头鲸,又名驼背鲸,Meta 将模型命名为 Humpback,也别有深意吧。

之所以称为指令回译,研究者表示这借鉴了机器翻译中经典的反向翻译方法,其中人类编写的目标句子会自动用模型生成的另一种语言的源句子进行注释。
图灵奖得主 Yann LeCun 高度概括了这项研究的方法,并称赞 Meta 这项工作为对齐研究做出重要贡献:

还有网友对这项研究进行了很好的概括:数据质量对大模型来说确实很重要,研究过程中,他们使用不同级别的过滤数据,微调了一个模型,结果表明,只有最好的样本才能得出比其他样本表现更好的模型。
该论文提出了一种需要两个步骤完成的新的数据增强范式。首先,必须拥有一组种子(指令、输出)对和语料库才能生成更多好的指令数据。

下图比较了 Humpback 与一些开源模型和专有模型。
下表4表明,本文方法在65B 和33B 模型尺度上都是非蒸馏模型中表现最好的模型。

下面我们看看具体方法。
方法简介
该研究提出了一种自训练方法(self-training),该方法通常假定可以访问基本语言模型、少量种子数据和未标记的样本集(例如网络语料库)。未标记数据往往是一大堆形态各异的文档,由人类编写,其中包括人类感兴趣的各种话题内容,但最重要的是没有与指令进行配对。
这里还有两个关键的假设,第一个假设是这个非常大的文本集(未标记样本集)存在一些子集,适合作为某些用户指令的生成样本。第二个假设是可以预测这些候选答案的指令,这些指令可以用于形成高质量样本对,以训练指令遵循模型。
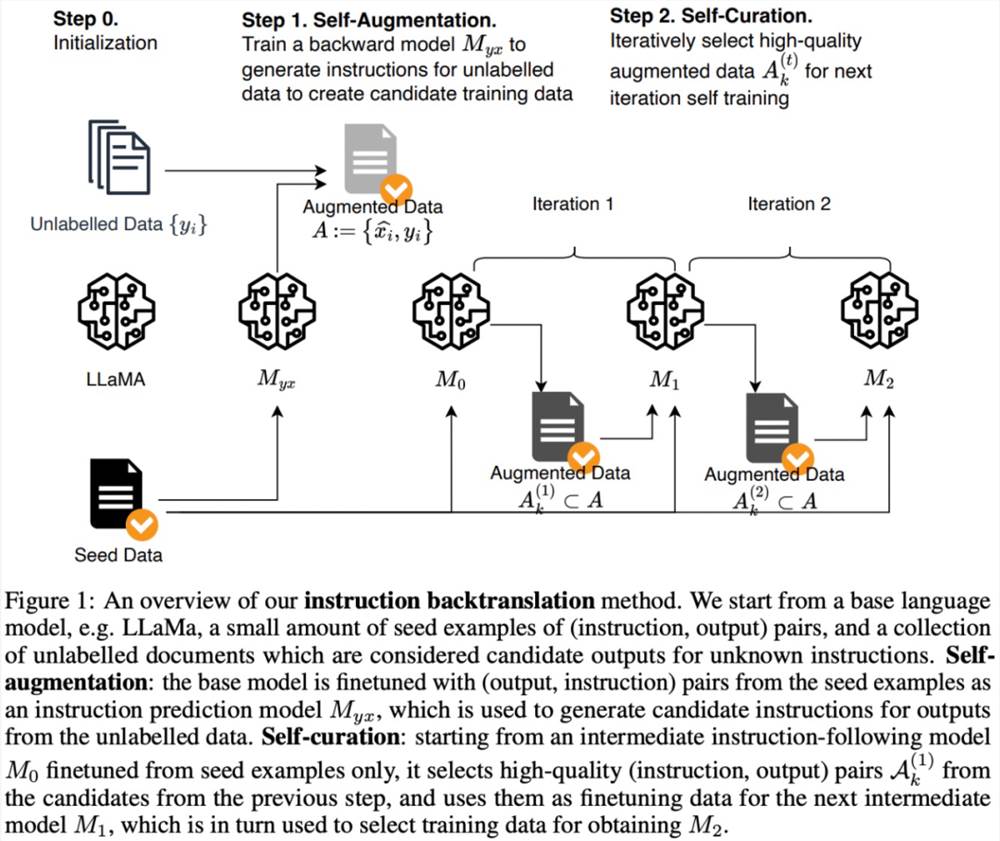
如下图1所示,该研究提出指令回译过程包含两个核心步骤:
自增强:为未标记的数据(即网络语料库)生成指令,以为指令调优产生训练数据对(指令 - 输出)。
自管理:自主选择高质量样本数据作为训练数据,以微调基础模型来遵循指令,这种方法是迭代完成的。
其中,自管理步骤采用的 prompt 如下表1所示:

实验及结果
本文的数据集主要包括种子数据和增强数据,具体信息如表2和图2所示:

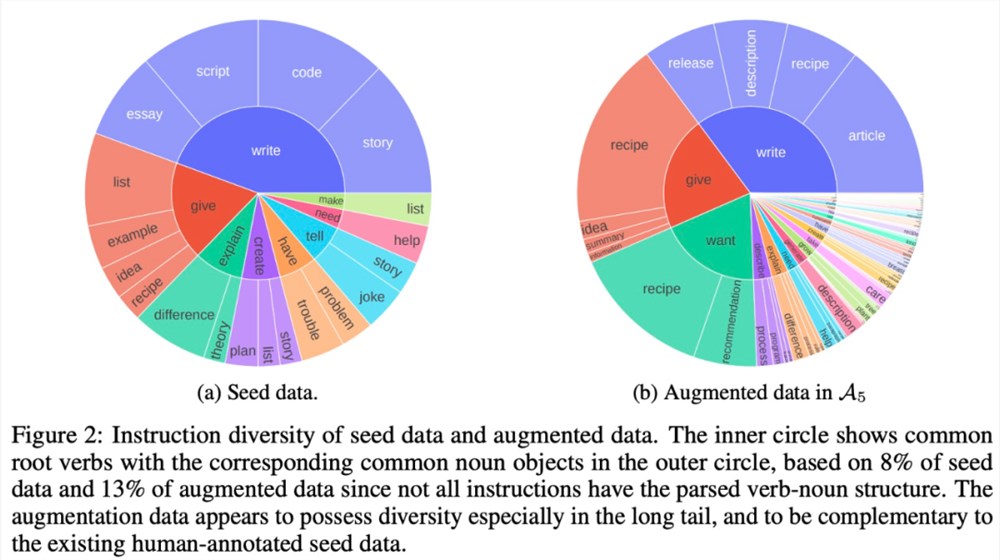
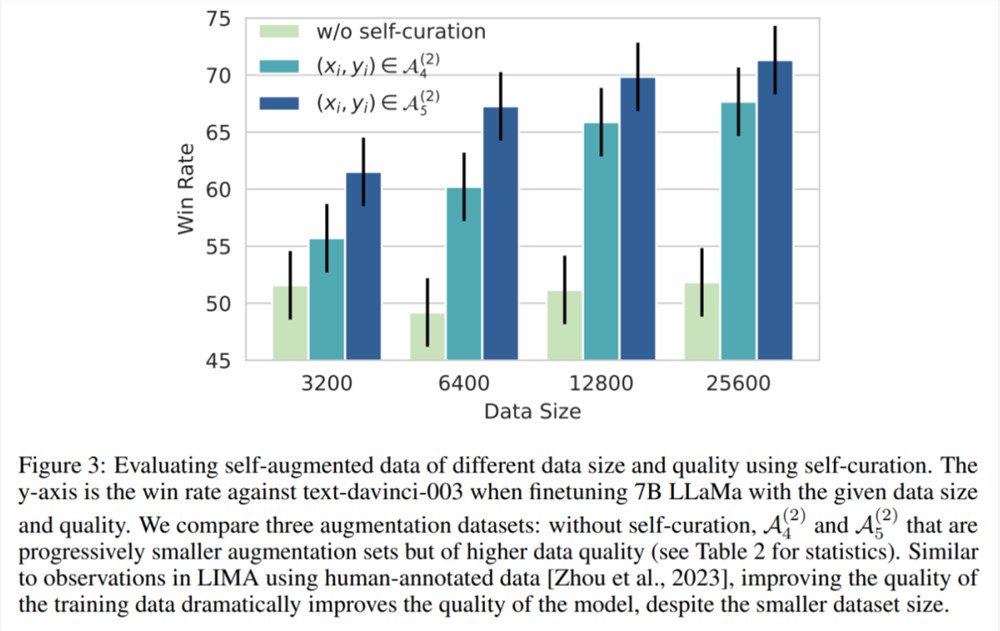
图3表示尽管扩大了数据规模,但没有自我管理(self-curation)的增强数据用来训练模型并不能提高指令跟随性能。
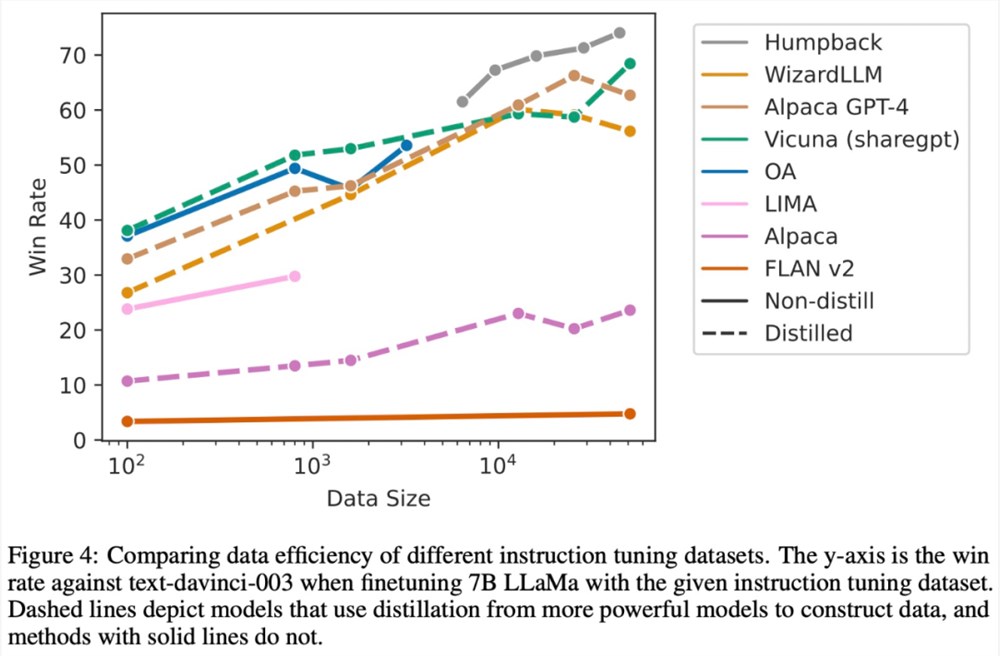
下图比较了不同指令调优数据集的数据效率。
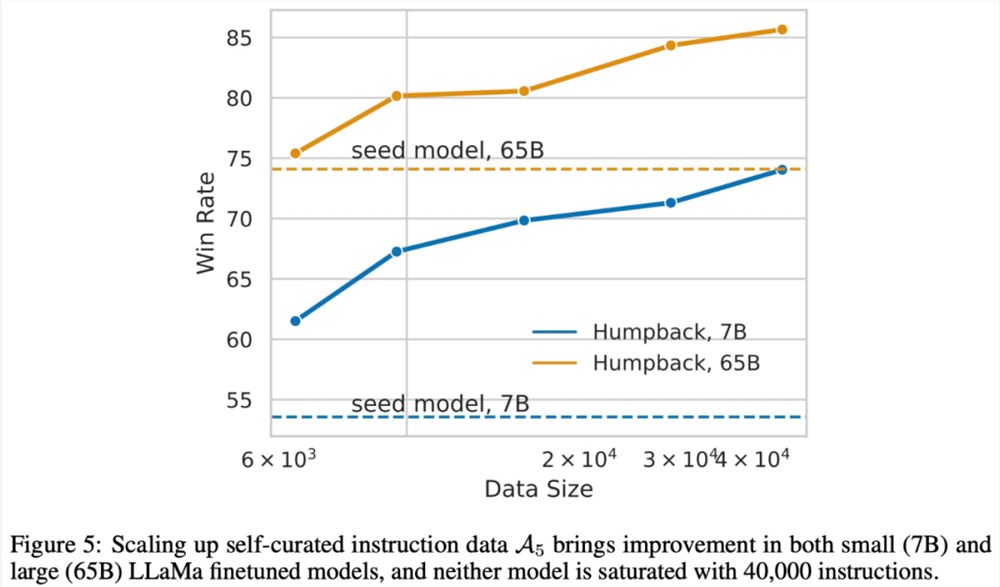
数据和模型的联合扩展:该研究发现在7B 模型中观察到的数据扩展趋势同样也适用于更大的模型。例如对65B 的种子模型增加高质量的增强数据会带来进一步的改进。
常识推理:该研究在五个常识推理基准上进行了测试,SIQA 、PIQA、Arc-Easy、Arc-Challenge 和 Openbook QA (OBQA) , 结果总结于表5中。结果表明,与基础模型相比,本文模型在社会推理等多个方面的表现有所提高。

MMLU:表6总结了不同模型在 MMLU(massive multitask language understanding)的结果。与基础模型相比,本文微调模型提高了零样本准确率,但在5个样本上下文示例中表现不佳。

Looi:基于ChatGPT ,能把手机变成智能机器人
划重点:⭐️LOOI是一款由ChatGPT技术驱动的机器人,具有生动的角色和生动的手势,能与用户互动并玩游戏。⭐️LOOI能感知用户的情绪,同时具有自己的特点,作为桌面助手,还可以提供15W无线充电、个性化时钟等功能。⭐️LOOI的多功能性和活泼性为工作和娱乐带来全新体验。LOOI机器人是一款充满活力的智能机器人,其结合手机,接入ChatGPT,有视觉能力,能互动。站长网2024-04-08 12:47:430000外卖小哥涌入抖音拍视频,已经有人火了
繁忙的都市中,车水马龙。外卖小哥们总是骑着小电驴匆匆而过,让蓝色或黄色的制服成为一抹鲜亮的剪影。然而近年来,他们开始以另一种方式出现在大众的视野中——在自媒体平台上分享自己的职业生活。从忙碌的送餐间隙到雨中的奔波,他们只需在头盔上固定一台运动相机,就可以用镜头拍摄工作中的点点滴滴,记录下辛勤的自我。站长网2024-07-08 11:09:250000Meta CEO 扎克伯格希望通过数字助手、智能眼镜和人工智能来帮助推动元宇宙
站长之家(ChinaZ.com)9月28日消息:Meta推出了新的人工智能工具和名人代言的数字助手,CEO马克·扎克伯格希望这些工具可以帮助启动元宇宙。在加利福尼亚州门洛帕克总部举行的MetaConnectVR开发者大会上,扎克伯格展示了AI软件、公司新款Quest3虚拟现实头戴设备以及最新款Ray-Ban智能眼镜。站长网2023-09-28 09:08:030002马斯克确认特斯拉Model 2明年上市 价格25000美元左右
特斯拉CEO埃隆·马斯克亲自确认,特斯拉旗下备受期待的入门级车型Model2将于2025年正式上市销售,该项目内部代号为“Redwood”。这一消息无疑为特斯拉粉丝和潜在购车者带来了极大的惊喜。站长网2024-04-29 17:19:150000Fullpath推出首款支持Chat-GPT4的产品 专为汽车经销商设计
Fullpath推出了首款支持Chat-GPT4的产品,专为汽车经销商设计,旨在改善在线购车体验和客户关系管理。AI工具经过训练,可以将互联网的大量知识与专有的Fullpath数据层相结合,以识别经销商数据库中的特定购物者并回答经销商的特定问题。将Chat-GPT4集成到Fullpath的CDXP平台将提高在线购车体验的效率和个性化,使客户和经销商等更加方便。站长网2023-04-20 12:05:470000