没有大招的火山引擎,拿下70%大模型玩家
有没有在开发大模型?在学习。
什么时候发布大模型?没计划。
当被问起自研大模型,字节跳动副总裁杨震原口风甚严。但席卷全球的这场大模型竞逐战,没有人会主动放弃阵地。
最新线索,在上海露出端倪。
火山引擎对外的最新技术、产品发布动作中,我们发现:炼大模型的基础设施,不仅已经在字节内部运转,还到了能够对外输出“技术秘籍”的阶段。
直观的数字,更能说明情况:
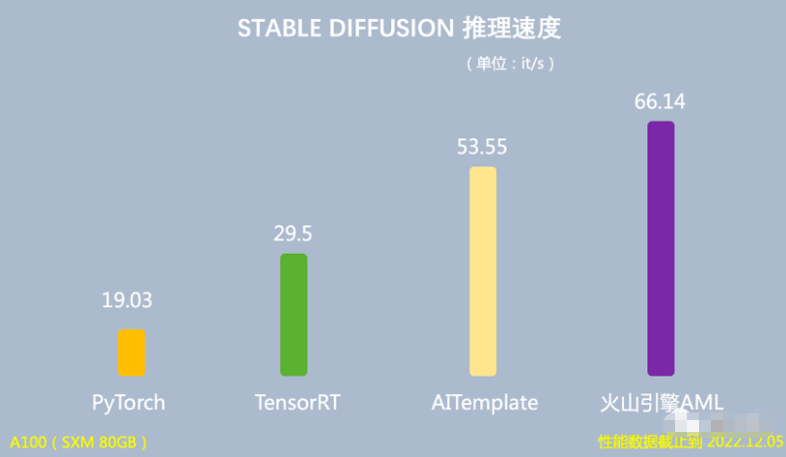
抖音2022年最火特效「AI绘画」,就是在火山引擎机器学习平台上训练而成。在训练场景下,基于Stable Diffusion的模型,训练时间从128张A100训练25天,缩短到了15天,训练性能提升40%。
在推理场景下,基于Stable Diffusion的模型,端到端推理速度是PyTorch的3.47倍,运行时对GPU显存占用量降低60%。
而就在全球最大云厂商AWS宣布,加入大模型竞赛,并且定位是“中立平台”,会接入Anthoropic、StabilityAI等模型厂商的大模型之际,量子位也获悉:
火山引擎,也在以类似路径探索大模型的落地,做法是用“机器学习平台 算力”为大模型企业提供AI基础设施。火山引擎总裁谭待透露,国内几十家做大模型的企业,七成已经在火山引擎云上。
大模型企业为什么会选择火山引擎?我们和火山引擎机器学习总监吴迪聊了聊。
大模型趋势,写在云计算的最新技术里
在AI方面,此番火山引擎重点提到了两个平台:机器学习平台和推荐平台。
机器学习平台
其中,机器学习平台涉及当下科技圈最热的两个话题——庞大算力的调度问题,以及AI开发的效率问题。
先来看算力调度。
说到大模型时代,OpenAI首席执行官Sam Altman曾发表观点称,“新版摩尔定律很快就要到来,宇宙中的智能每18个月翻一倍”。
而这背后,模型训练开发所需要的算力规模,可想而知。
但用算力,实际上并不是一个纯堆硬件的事情。举个例子,如果机器学习框架跟底层的硬件是各自独立的一套,那在训练AI模型时,由于通信延迟、吞吐量等问题,训练效率就无法最大化。
简单来说,就是很多算力会在这个过程中被浪费掉。
解决方法,是软硬一体。
吴迪介绍,火山引擎的自研DPU,将算力层和平台层统一起来进行了整体优化。比如,将通信优化的算法直接写到网卡硬件中,以降低延迟、削减拥塞。
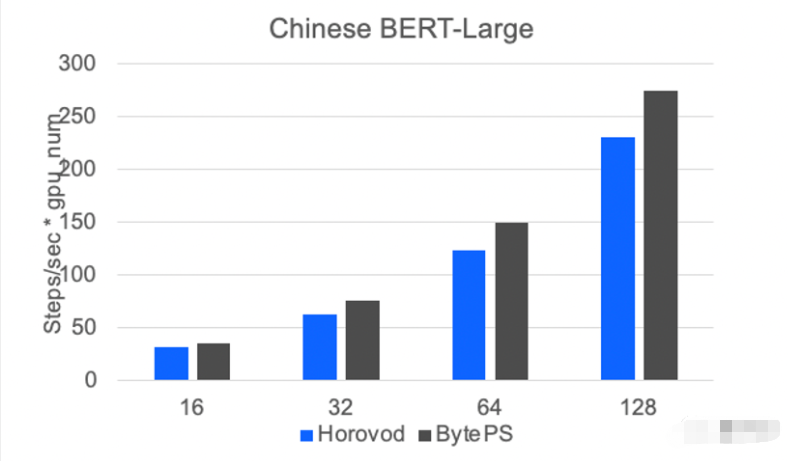
测试数据显示,火山引擎的通信框架BytePS,在模型规模越大时,收益会越高。
而在AI开发效率方面,火山引擎推出了Lego算子优化。
具体而言,这一框架可以根据模型子图的结构,采用火山引擎自研高性能算子,实现更高的加速比。
前文提到的抖音特效训练效率的提升,就得益于此:
在推理场景下,使用Lego算子优化,可以将基于Stable Diffusion模型的端到端推理速度提升至66.14it/s,是PyTorch推理速度的3.47倍,运行时GPU显存占用量降低60%。
在训练场景下,在128张A100上跑15天,模型即可训练完成,比当时最好的开源版本快40%。
目前,火山引擎这一套机器学习平台,已经部署到了MiniMax的文本、视觉、声音三个模态大模型训练和推理场景中。
MiniMax联合创始人杨斌说,依托火山引擎机器学习平台,MiniMax研发了超大规模的大模型训练平台,高效支撑着三个模态大模型每天千卡以上的常态化稳定训练。在并行训练上实现了99.9%以上的可用性。除了训练以外,MiniMax也同步自研了超大规模的推理平台,目前拥有近万卡级别的GPU算力池,稳定支撑着每天上亿次的大模型推理调用。
有稳健的大模型基础设施,MiniMax从零开始自主完整地跑通了大模型与用户交互的迭代闭环,实现从月至周级别的大模型迭代速度,和指数级的用户交互增长。MiniMax和火山引擎一起为大模型训练搭建了高性能计算集群,一起致力于提升大模型训练的稳定性,保证了千卡训练的任务稳定运行数周以上。
从今年开始,MiniMax又和火山引擎在网络和存储上进行了更深入的优化合作,实现更低的网络延迟,将带宽利用率提升了10%以上。
吴迪坦言,“软硬一体、通信优化、算子优化都不是新概念,火山引擎机器学习平台也没有特别牛、特别超前的大招。我们靠的就是务实严谨地不断把细节做扎实,把重要技术锤炼到位,这样才能赢得客户的信任。”
推荐平台
机器学习平台之外,这次在自家看家本领——推荐系统上,火山引擎对外拿出了推荐系统全套解决方案:从物料管理,到召回排序,再到效果分析、A/B测试和模型算法,都可以开箱即用。
而作为产业界近年来落地最为成功的AI应用之一,在推荐领域,深度学习模型越来越大、越做越深的趋势,也早已显现其中。
吴迪介绍,由于推荐是一个高度定制化的场景,每个人的兴趣、画像都有单独的embedding,因此大规模稀疏模型很重要。
同时,由于真实世界在时刻变化,因此背后又存在一重实时训练的挑战。
这都对传统的深度学习框架提出了很大的挑战。
为此,火山引擎不仅将以上工程实现进行封装,推出了基于TensorFlow的机器学习训推一体框架Monolith,还拿出了针对智能推荐的高速GPU训练和推理引擎——Monolith Pro。
值得关注的是,Monolith Pro覆盖的场景包括:
针对关键场景的超大模型,使用高密度GPU进行超高速训练;
覆盖更多场景的模型,混合使用CPU GPU高速训练。
吴迪进一步解释说,推荐模型需要做大做深,才能对众多事物之间的关联有更好的理解——这一点,如今已经在GPT引发的一系列现象上得到充分验证。
因此在现在这个时间点,对于任何正在开展推荐广告业务的公司而言,高价值的数据是一方面,另一方面,找到训练更强、更大、更实时模型的方法,对整个系统进行智能化升级,已经到了一个关键期。


所以,Monolith Pro又具体能实现怎样的效果?吴迪透露,基于Monolith Pro,抖音内部的某重要广告场景,原本一次广告训练需要15个月样本,训练时间为60小时,现在只需要5小时就能完成。
工程师可以做到上午启动训练,下午就能开A/B测试了(笑)。
大模型改写云计算规则
由ChatGPT而起,在海内外一波波大模型的发布中被推至高潮,一场新的技术变革已然势不可挡。
云计算,作为一个早已深深与AI关联的业务,站立桥头,也最早面临着规则被重新改写的境况。
随着大模型能解决越来越多下游任务,如何用大模型,又成为了新的问题:无论是训练还是推理,大模型都需要很强的基础设施支持。
云计算成为了最便捷的上车途径。同时,云厂商们也势必要面向大模型,重塑自身云产品的面貌。
吴迪认为,作为一项技术,未来大模型会是百花齐放的局面。丰富的需求会催生出若干成功的模型提供商,深入满足千行百业的业务需求。
与此同时,大模型的应用也面临若干基础问题:
基础大模型可能还需要用更多高质量数据,做进一步的增量学习和finetune,才能真正在产业中落地应用。整个流程需要更为敏捷和易用。
大模型将成为大数据时代的“中央处理器”,它能够控制插件、接口,以及更丰富的下游模型。大模型需要这些“手”和“脚”,才能进入我们生活的方方面面。
随着大模型应用的增多,数据安全和信任将成为产业关注的焦点。
推理效率。大模型的训练成本高昂,但长期来看,全社会投入在大模型推理上的开销将逐渐超过训练成本。在微观上,能以更低单位成本提供大模型相关服务的公司,将获得竞争优势。
但可以肯定的是,大模型改造各行各业的浪潮已至。
有人正面迎战,有人从更底层的问题出发,尝试破解新的问题和挑战。
共同点是,大模型的潮头来得迅猛激烈,但在第一线迎接风暴的,从来不是没有准备之人。
现在,到了检验真正AI能力和积累的时刻。至少在与大模型相伴相生的云计算领域,精彩才刚刚开幕。
—完—
AMD推出Versal AI Edge芯片 专为太空应用设计、2024年投入使用
文章概要:1.AMD推出VersalAIEdge芯片,针对太空应用进行AI推断,具备辐射耐受性和紧凑设计。2.VersalAIEdgeXQRVE2302是首款专为太空应用设计的自适应SoC芯片,具备卓越性能和安全功能。3.该芯片支持机器学习应用,可在太空任务中转化传感器数据为有价值的信息,预计将于2024年投入使用。站长网2023-09-22 10:17:250000一印度CEO用AI机器人取代90%客服人员遭网友吐槽
一位印度CEO因选择人工智能机器人而不是人类员工受到批评。据了解,SuumitShah是一家电子商务网站Dukaan的创始人,他在Twitter上表示,该机器人已经取代了90%的客服人员,并大大提高了客户查询的首次响应和解决时间。这条推文引发了网上的愤怒声浪。此举发生在人们对人工智能夺走人们工作的担忧与讨论之际,尤其是在服务行业中。站长网2023-07-13 06:58:210000苹果确认漏洞阻止了儿童的屏幕时间限制
苹果确认存在漏洞,儿童能够绕过屏幕使用时间限制的设置。据《华尔街日报》报道,家长们发现通过家庭共享系统设置的一些屏幕使用时间限制无法正确保存数月。苹果本应在5月份解决这个问题,但该漏洞仍然存在。站长网2023-07-31 10:23:400000接入Llama 2等33个大模型,上线Prompt模板,百度智能云千帆大模型平台重磅升级
最近,Meta开源的Llama2系列模型引发了不小的轰动。这些模型包含7B、13B、70B三种版本,最大的70B版本性能接近GPT-3.5,小一点的版本甚至可以在移动端运行,且整个系列都允许商用,有望成为众多大模型应用的底层支撑。很多人预言说,「大模型的安卓时代就要来了」。站长网2023-08-04 17:57:460001香港大学和微软推高效声音转换方法CoMoSVC 歌声随意切换
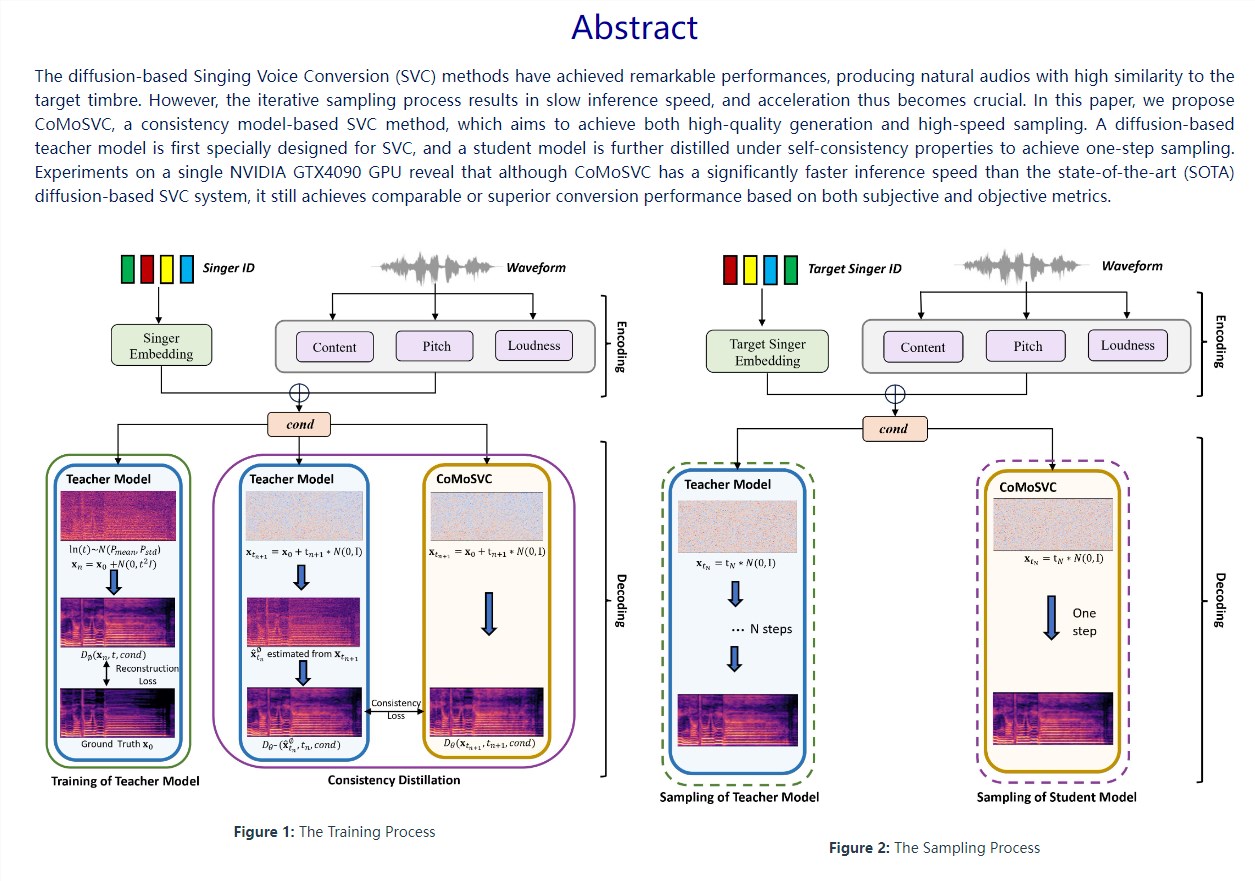
CoMoSVC是一种能够将一个人的歌声转换成另一个人的歌声的创新技术。这个项目是由香港大学和微软亚洲研究员共同开发的,它在高质量音频转换和快速处理速度之间找到了平衡,是语音转换领域的重大进步。站长网2024-01-04 15:31:450000