浏览器就能跑大模型了,陈天奇团队发布WebLLM,无需服务器支持
现在,只需一个浏览器,就能跑通“大力出奇迹”的大语言模型(LLM)了!
不仅如此,基于LLM的类ChatGPT也能引进来,而且还是不需要服务器支持、WebGPU加速的那种。
例如这样:
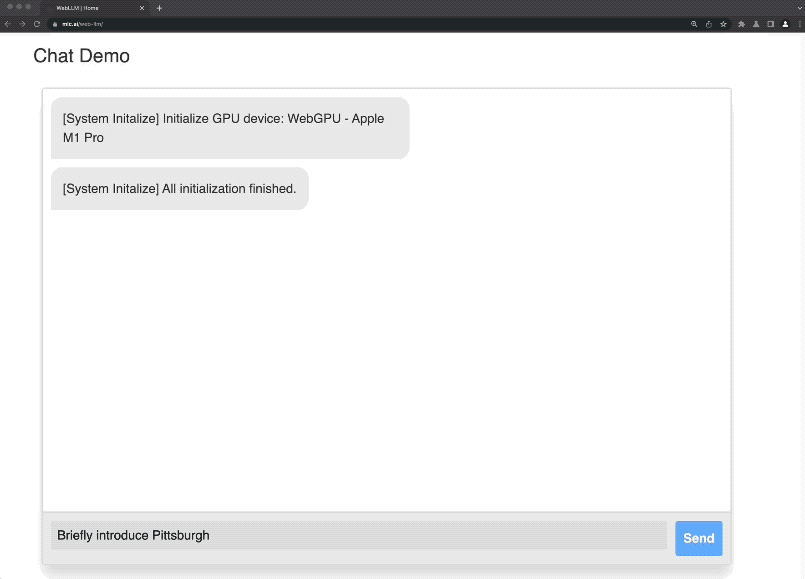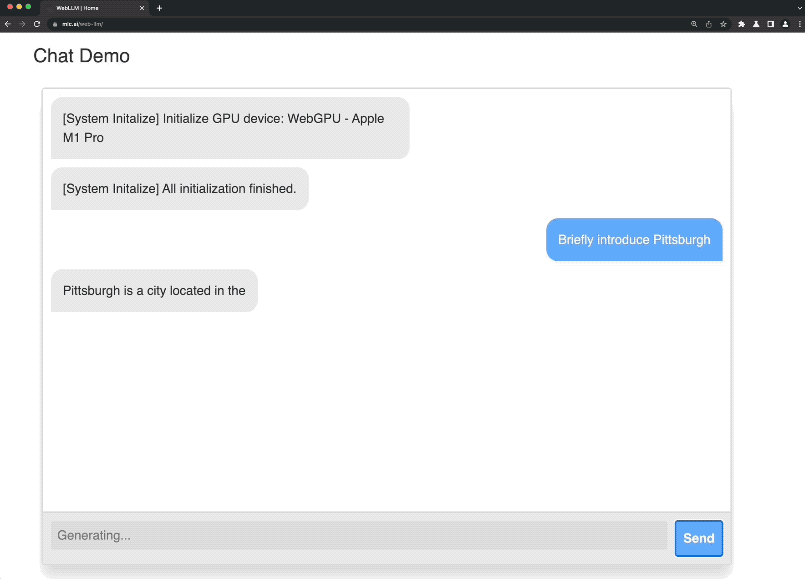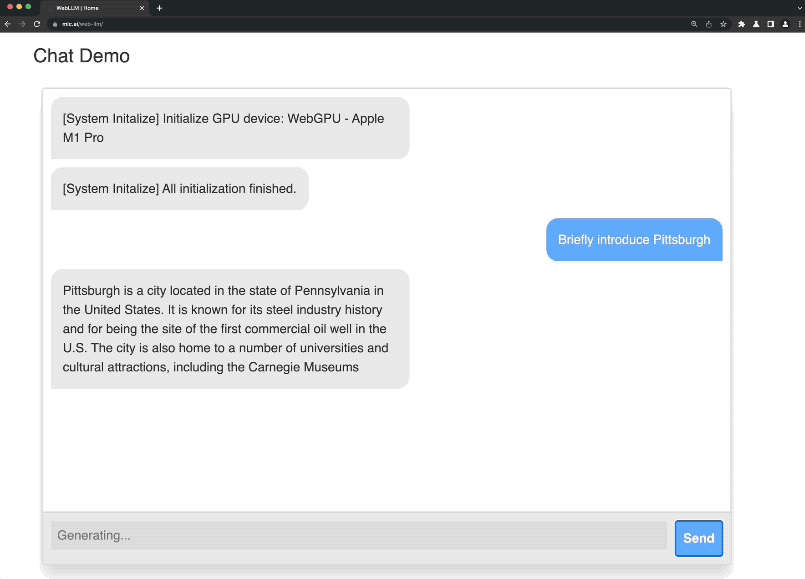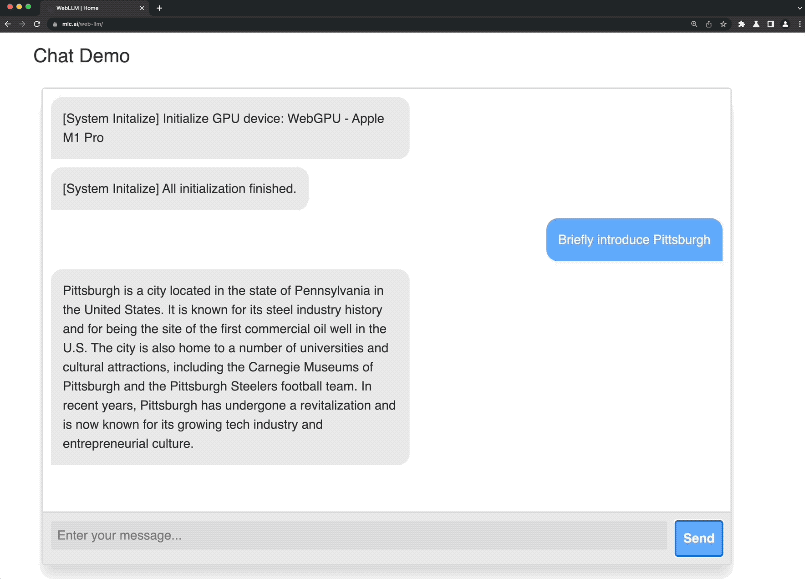
这就是由陈天奇团队最新发布的项目——Web LLM。
短短数日,已经在GitHub上揽货3.2K颗星。

一切尽在浏览器,怎么搞?
首先,你需要下载Chrome Canary,也就是谷歌浏览器的金丝雀版本:
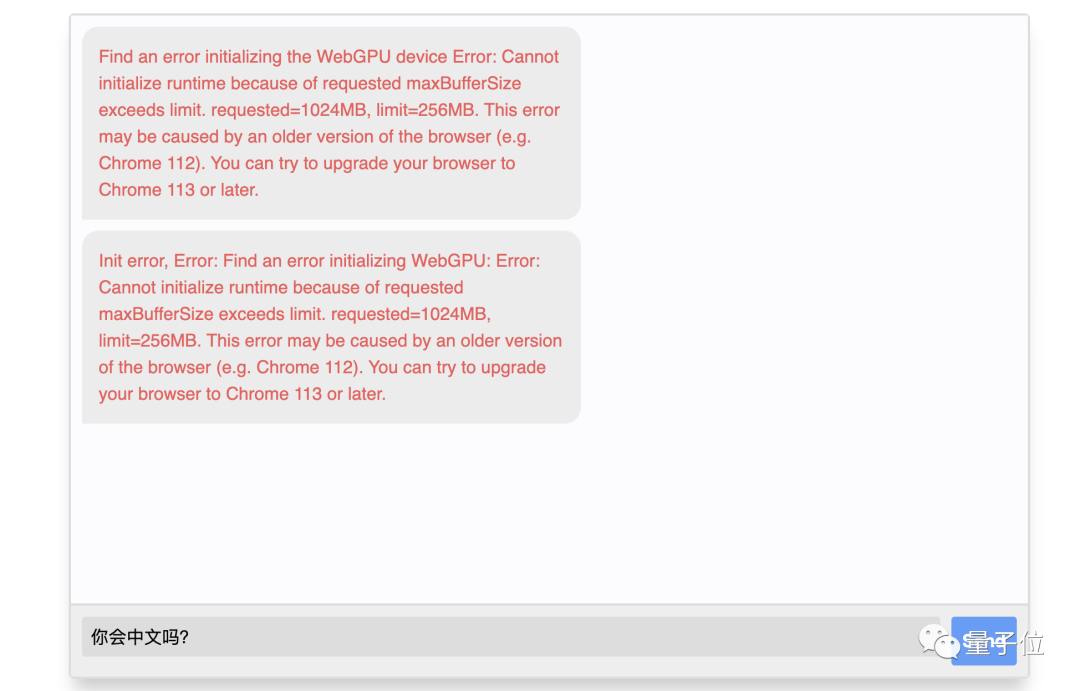
因为这个开发者版本的Chrome是支持WebGPU的,否则就会出现如下的错误提示:
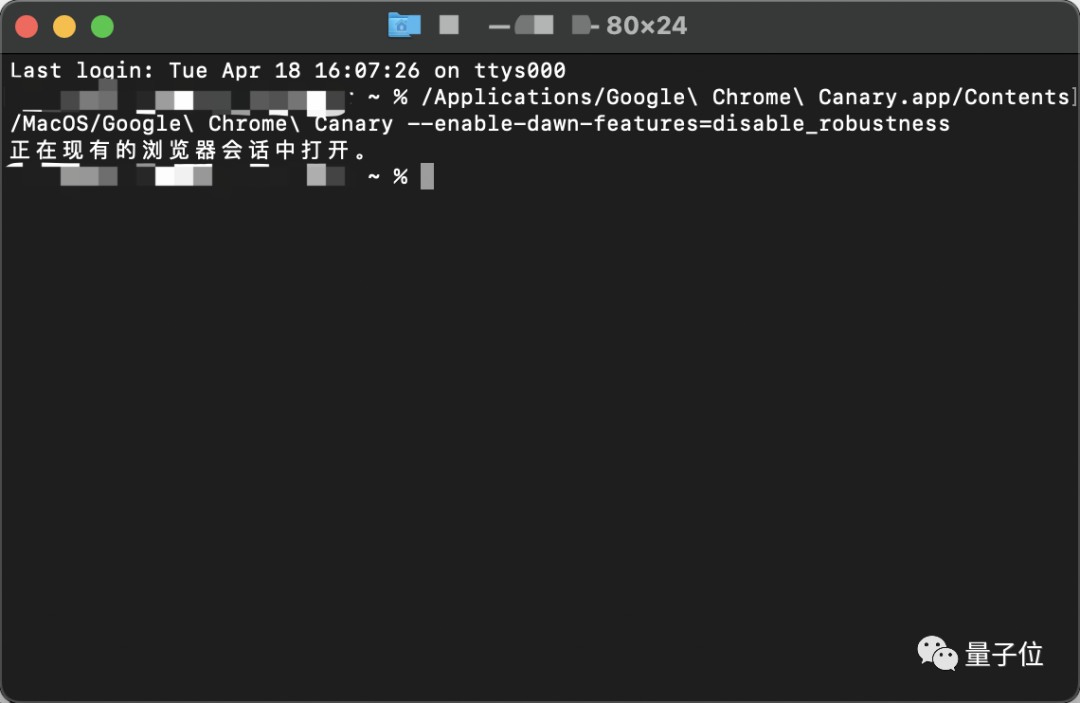
在安装完毕后,团队建议用“终端”输入如下代码启动Chrome Canary:
/Applications/Google\Chrome\Canary.app/Contents/MacOS/Google\Chrome\Canary—enable-dawn-features=disable_robustness
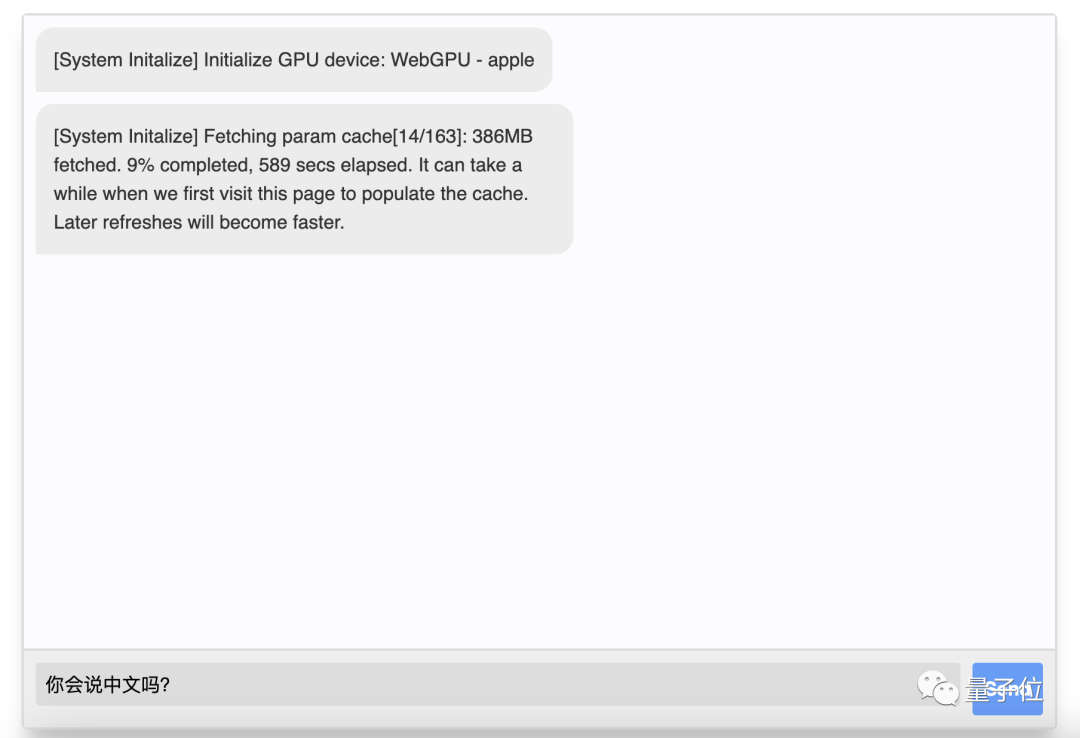
启动之后,便可以来到官网的demo试玩处开始体验了。
不过在第一次展开对话的时候,系统还会出现一个初始化的过程(有点漫长,耐心等待)。
机器学习编译(MLC)是关键
接下来,我们来看一看Web LLM如何做到“一切尽在浏览器”的。
根据团队介绍,其核心关键技术是机器学习编译(Machine Learning Compilation,MLC)。
整体方案是站在开源生态系统这个“巨人肩膀”上完成的,包括Hugging Face、来自LLaMA和Vicuna的模型变体,以及wasm和WebGPU等。
并且主要流程是建立在Apache TVM Unity之上。

团队首先在TVM中bake了一个语言模型的IRModule,以此来减少了计算量和内存使用。
TVM的IRModule中的每个函数都可以被进一步转换并生成可运行的代码,这些代码可以被普遍部署在任何最小TVM运行时支持的环境中(JavaScript就是其中之一)。
其次,TensorIR是生成优化程序的关键技术,通过结合专家知识和自动调度程序快速转换TensorIR程序,来提供高效的解决方案。
除此之外,团队还用到了如下一些技术:
启发式算法:用于优化轻量级运算符以减轻工程压力。int4量化技术:用来来压缩模型权重。构建静态内存规划优化:来跨多层重用内存。使用Emscripten和TypeScript :构建一个在TVM web运行时可以部署生成的模块。……
上述所有的工作流程都是基于Python来完成的。
但Web LLM团队也表示,这个项目还有一定的优化空间,例如AI框架如何摆脱对优化计算库的依赖,以及如何规划内存使用并更好地压缩权重等等。
团队介绍
Web LLM背后的团队是MLC.AI社区。
据了解,MLC.AI 社区成立于2022年6月,并由 Apache TVM 主要发明者、机器学习领域著名的青年学者陈天奇,带领团队上线了 MLC 线上课程,系统介绍了机器学习编译的关键元素以及核心概念。

值得一提的是,该团队此前还做过Web Stable Diffusion,链接都放在下面了,赶快去体验吧~
Web LLM体验地址:https://mlc.ai/web-llm/
Web Stable Diffusion体验地址:https://mlc.ai/web-stable-diffusion/
参考链接
[1]https://twitter.com/HongyiJin258/status/1647062309960028160
[2]https://github.com/mlc-ai/web-llm
微软推出数字水印工具保护政治运动免受深度伪造的威胁
划重点:-🌐微软将推出数字水印工具,为政治运动提供保护,防范深度伪造,并提供网络安全服务。-🔐ContentCredentialsasaService将于明年春季推出,首先提供给政治运动使用,通过元数据附加信息,包括内容的产生和创作者信息。-🚀微软将与组织合作,在Bing上推出可靠选举信息网站,并支持法案禁止AI制作虚假政治广告。站长网2023-11-10 16:41:050000腾讯视频入驻抖音 此前双方宣布达成合作
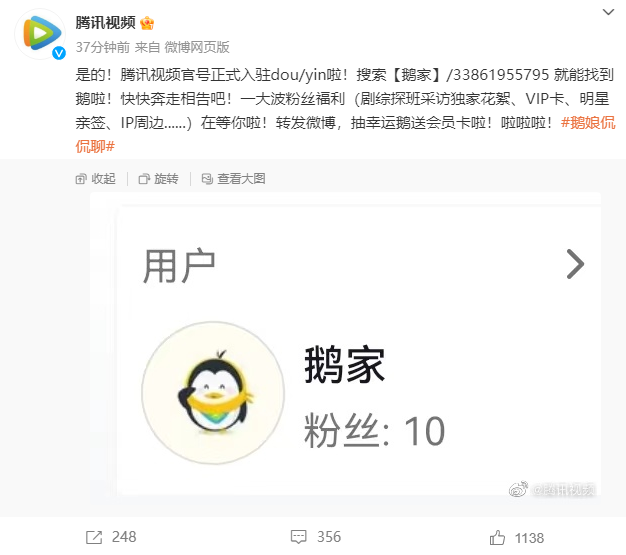
今日下午,腾讯视频官方宣布正式入驻抖音,用户可以在抖音搜索33861955795,就能找到腾讯视频官方抖音账号“鹅家”。4月7日,抖音宣布和腾讯视频达成合作,双方将围绕长短视频联动推广、短视频二次创作等方面展开探索。站长网2023-04-12 12:08:450000GPT-4推理提升1750%!普林斯顿清华姚班校友提出全新「思维树ToT」框架,让LLM反复思考
2022年,前谷歌大脑华人科学家JasonWei在一篇思维链的开山之作中首次提出,CoT可以增强LLM的推理能力。但即便有了思维链,LLM有时也会在非常简单的问题上犯错。最近,来自普林斯顿大学和GoogleDeepMind研究人员提出了一种全新的语言模型推理框架——「思维树」(ToT)。站长网2023-05-22 17:40:320004小米龙铠架构上热搜 小米14 Ultra首发:整机强度提升
小米14Ultra全新亮相,其引人瞩目的特性之一是首次搭载了小米龙铠架构,这一创新设计在抗弯、耐摔、耐磨三大方面均实现了显著的提升。为了增强手机的抗弯性能,小米14Ultra选用了高强度铝合金6M42作为中框材料,并结合了CNC一体成型技术。这种独特的组合使得手机的抗弯性能大幅提升,据官方数据,提升幅度高达100%。站长网2024-02-21 11:50:000000Character.AI 加入 AI 群聊功能:用户可与多个人工智能角色相互交谈
Character.AI是一家由前GoogleAI研究人员创建的AI聊天机器人初创公司,由a16z支持,今天为其订阅者推出了一项新功能。该聊天机器人平台提供具有独特个性的可定制人工智能伴侣以及可定制的工具,现在提供群聊体验,用户和他们的朋友可以同时与多个人工智能角色聊天。图片来自Character.ai站长网2023-10-12 09:04:560000