DeepMind研究人员提出ReST算法:用于调整LLM与人类偏好对齐
文章概要:
1. ReST是一种新方法,通过成长式批量强化学习来调整大型语言模型与人类偏好保持一致。
2. ReST使用基于奖励模型的评分函数来过滤策略生成的样本,奖励模型通过学习人类偏好得到。
3. ReST内循环使用离线强化学习目标(如DPO)进行策略优化,外循环通过采样增长数据集。
近年来,大型语言模型在生成流畅文本和解决各种语言任务上展现出惊人的能力。但是,这些模型并不总是与人类的偏好和价值观相一致,如果不加以适当指导,可能会生成有害或不合需求的内容。如果将语言模型与人类偏好对齐,既可以提高模型在下游任务上的表现,也可以改善模型的安全性。
为此,DeepMind的研究人员提出了一种称为Reinforced Self-Training(ReST)的新方法,旨在将语言模型与人类偏好对齐。ReST受成长式批量强化学习的启发,包含内外两个循环:内循环在给定数据集上改进策略,外循环通过从最新策略中采样来增长数据集。
具体来说,ReST使用基于奖励模型的评分函数来对策略生成的样本进行排名和过滤。奖励模型通过从各种源头(比如评分、排序、比较)收集人类偏好进行训练。评分函数还可以结合其他因素,比如样本的多样性或长度惩罚,以确保数据集的平衡。
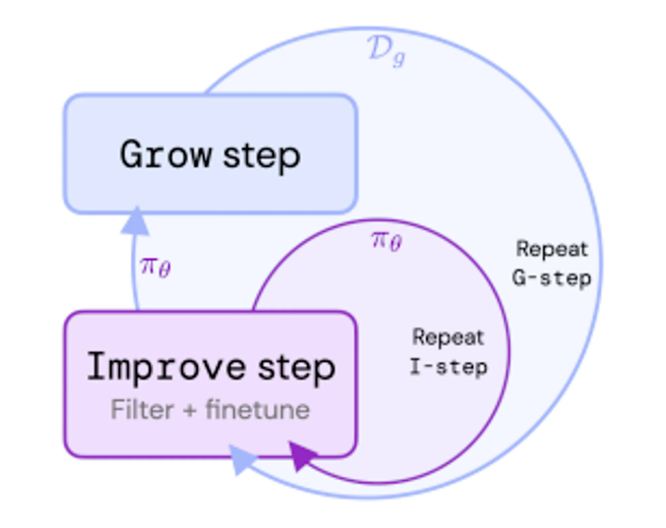
ReST 可以在内部循环中使用不同的离线 RL 目标:ReST 是一种通用方法,可以在内部循环中使用任何离线 RL 目标,例如 DPO(直接偏好优化)、BCQ(批处理约束 Q 学习)或 CQL(保守 Q 学习)。研究人员在几项任务上比较了这些目标,发现DPO在大多数情况下表现最佳。
ReST是一种使用不断增长的批量RL使LLM与人类偏好保持一致的新方法。与现有的RLHF方法相比,ReST具有几个优势,例如计算效率,数据质量和奖励黑客的鲁棒性((Robustness))。
ReST可以提高LLM在各种任务上的性能和安全性。。ReST可以提升语言模型在诸如机器翻译、摘要生成或对话生成等任务上的性能和安全性。同时,ReST也很简单易实现,只需要能对模型进行采样和评分即可。
ReST简单易行。ReST 几乎没有需要调整的超参数,并且简单可靠。ReST 只需要能够从模型中采样并对其要实现的样本进行评分。
库克总薪较前年缩水超3500万美元 同比下降 36%
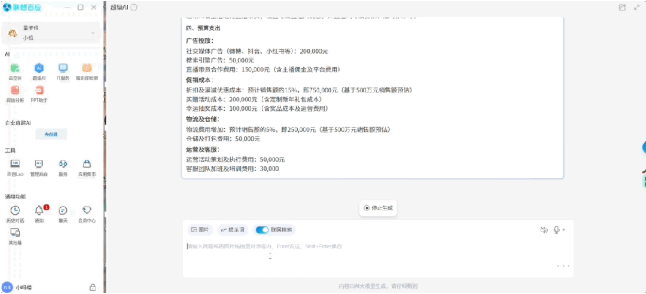
苹果公司近日发布了年度报告,详细披露了公司高管薪酬、股东提案等重要信息。其中,首席执行官蒂姆·库克的薪酬成为关注的焦点。根据报告,库克在2023年的总收入为6320万美元,比2022年的9940万美元收入下降了约36%。虽然这一数字高于他2023年目标薪酬4900万美元,但与2022年的收入相比,仍然有所下滑。0001文本生成8K、360度全景世界!Model 3重磅发布
知名生成式AI平台BlockadeLabs在官网重磅发布了全新模型——Model3。与Model2相比,Model3的生成效果实现质的提升,原生支持超高清8192x4096分辨率,增强了文本提示器能更好的描述生成世界,并且大幅度减少了生成世界的灰度值,使建筑、风景、人物等看起来更加高清、细腻。站长网2024-04-22 09:03:070001在线支付服务商Klarna推出AI图像搜索工具
划重点:🛍️Klarna推出新功能,包括名为“ShoppingLens”的AI图像搜索工具。📹ShoppableVideo扩展到欧洲市场,提供个性化视频体验。🌐Klarna引入实体店内产品扫描功能、新的返现计划、单一登录解决方案以及可持续性过滤器。站长网2023-10-12 15:24:300000报道称配备3nm芯片的MacBook Pro将于今年晚些时候推出
据macrumors报道,苹果计划在2023年第三季度发布一款新的MacBookPro,该款笔记本电脑将搭载由台积电先进的3nm工艺制造的升级芯片,这是根据今天分享的即将发布的DigiTimes报告的预览。预览称,“据业内人士透露,苹果计划在第三季度推出的下一代MacBookPro将采用3nm处理器”。站长网2023-07-18 12:30:490000这届打工人太难带?全能智能体出手了
打工人捅娄子,现在都能靠AI来补救了!领导马上就要的促销方案,唰一下就写好了。不仅能直接导出Word:还能一键生成PPT。职场新人不熟悉的电脑设备,还总是遇到bug,截图问AI,它就能给出具体的解决方案。和请教ChatGPT不同,它能主动识别设备信息,结合具体情况回答。不知道如何操作还能继续问。还有连不上打印机、系统报错这种很细小的问题,现在都可以求助AI。站长网2024-12-31 18:32:350000