研究:AI模型仍不擅长生成干净代码 GPT-4的API误用率达62%
文章概要:
1. AI模型在回答Java编码问题时,仍存在许多API误用问题。GPT-3.5和GPT-4的API误用率分别达到49.83%和62.09%。
2. Llama2API误用率最低,但由于它生成的代码较少,误导性很大。一旦生成更多代码,其误用率也大幅上升。
3. 添加相关API使用示例能稍微改善结果,但仍有改进空间。代码的可靠性和稳健性仍是难题。
近期,计算机科学家对几个大型语言模型在StackOverflow的Java编码问题上的回答进行了评估,结果发现这些模型的代码质量仍然不尽如人意。

研究人员收集了1208个StackOverflow上的Java编码问题,这些问题涉及24个常见的Java API。然后他们用4个可生成代码的大型语言模型(GPT-3.5、GPT-4、Llama2和Vicuna-1.5)进行了回答,并根据自己开发的API检查器RobustAPI对回答进行评估。RobustAPI旨在评估代码的可靠性,即抵御失败和意外输入的能力,以及承受高工作负载的能力。
加州大学圣地亚哥分校的研究人员测试了 OpenAI 的 GPT-3.5和 GPT-4,以及大型模型系统组织的两个开放模型:Meta 的 Llama2和 Vicuna-1.5。他们对这组问题进行了三种不同的测试:零样本,其中输入提示中没有提供正确的 API 使用示例;one-shot-imrelevant,其中提供的示例与问题无关;一次性相关,其中提示中提供了正确的 API 使用示例。
这些模型在零样本测试中表现出的总体 API 误用率如下:
GPT-3.5(49.83%);GPT-4(62.09%);Llama2(0.66%);和Vicuna-1.5 (16.97%)。
简单的说就是,在零样本测试中,GPT-3.5和GPT-4的API误用率较高,分别达到49.83%和62.09%。
Llama2的误用率最低,只有0.66%,但这主要是因为其大多数回答并不包含任何代码。
在添加不相关示例的一次样本测试中,各模型的误用率有所上升,尤其是Llama2上的升幅最大。这说明一旦生成了更多代码,Llama2的误用问题也显现出来。
对于一次性无关测试,误用率分别为:
GPT-3.5(62.00%);GPT-4(64.34%);Llama2(49.17%);和 Vicuna-1.5(48.51%)。
而在提供相关示例的一次样本测试中,误用率有所下降,但仍普遍存在,误用率如下:
GPT-3.5(31.13%);GPT-4(49.17%);Llama2(47.02%);和 Vicuna-1.5(27.32%)。
研究认为,大型语言模型代码生成能力的提升与代码可靠性和稳健性之间存在明显差距。模型生成的代码充其量只保证语义上的正确性,而忽视了意外输入和高负载环境下的稳定可靠性要求。改善这一问题仍有很大的空间。语言模型的代码生成还需要在工程质量上下功夫,而不仅仅追求生成更多代码。
用AI模型辅导英语口语 以色列创企Loora完成925万美元融资
以色列的语言学习初创公司Loora最近宣布完成了925万美元的种子轮融资。这轮融资由早期投资者Emerge领投,TwoLanternsVenturePartners和KaedanCapital是主要跟投方,还有一些天使投资人也参与了投资。站长网2023-07-04 15:58:180000可口可乐与微软签署11亿美元协议,推动生成式人工智能技术
划重点:⭐️可口可乐与微软签署了一项价值11亿美元的协议,旨在改善云计算,并在全球范围内采用科技巨头的生成式人工智能能力。⭐️可口可乐已经将其所有应用程序转移到微软Azure,同时大多数独立装瓶合作伙伴也在追随。⭐️这一合作意味着可口可乐将探索生成式人工智能驱动的数字助手在AzureOpenAI服务上的应用,以帮助员工改善客户体验和简化运营。站长网2024-04-24 14:13:540000Domo AI上线新功能 只需一张照片和视频即可让人物动起来
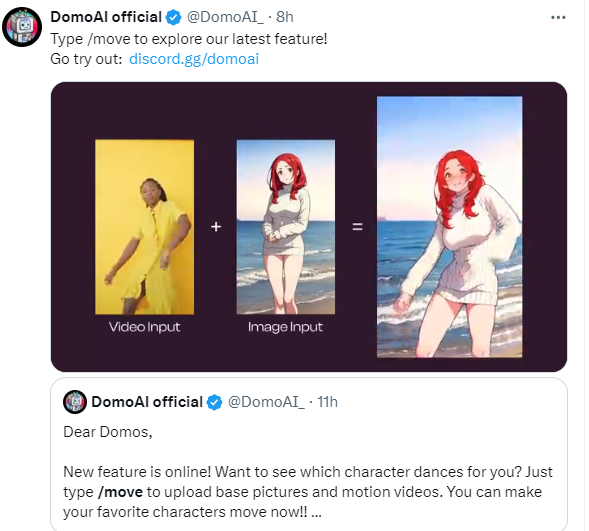
DomoAI最近推出了一项令人兴奋的新功能,能够将静态人像变得栩栩如生。这项创新技术只需要一张静态照片和一个参考的动态视频,就能够将静态照片中的人物替换成动态视频中的人物,使其动起来。站长网2024-03-25 10:17:060002微软确认 Windows Copilot 并非所有人都能在 Windows 11 上使用
站长之家(ChinaZ.com)10月9日消息:WindowsCopilot是Windows11Moment4更新的一部分,于9月26日开始向普通用户推出。但并非所有人都可以使用Copilot。目前,Copilot仅在美国(以及北美)、英国以及亚洲和南美洲的一些国家可用。站长网2023-10-09 11:37:280000董宇辉称不方便回应东方甄选二选一
近日,有媒体报道称,东方甄选内部流出的一份聊天记录显示,俞敏洪目前面临要保CEO孙东旭还是要保主播董宇辉的二选一的处境。这一消息引发了广泛关注。据语音转文字的截图提到,“宇辉回不去东方甄选了”。针对这一消息,董宇辉本人回应称不方便回应。此外,关于所谓“小作文”的来源也引发了争议。究竟是董宇辉所写,还是东方甄选小编所写?这一问题引发了董宇辉粉丝、东方甄选小编以及公司的多方论战。0000