全球大型网站正在阻止 OpenAI 等人工智能爬虫访问其内容
根据人工智能内容检测器 Originality.AI 的最新数据,全球前 1000 个网站中有近 20% 阻止爬虫机器人收集网络数据用于 AI 服务。

在缺乏明确法律或监管规定管理 AI 使用版权材料的情况下,大小不一的网站都自行采取措施。
OpenAI 于 8 月初推出了其 GPTBot 爬虫,并宣布所收集到的数据「可能被用于改进未来模型」,承诺排除付费内容并指导网站如何禁止该爬虫。随后,包括《纽约时报》、路透社和 CNN 等知名新闻网站开始阻止 GPTBot,并且许多其他网站也效仿。
根据 Originality.AI 的数据,在全球前 1000 个最受欢迎的网站中,阻止 OpenAI ChatGPT bot 的数量从 8 月 22 日 9.1% 增加到 8 月 29 日 12%。封锁 ChatGPT bot 的最大网站是亚马逊、Quora 和 Indeed。数据显示,更大型的网站更有可能已经封锁了 AI 爬虫机器人。
Common Crawl Bot 是另一个定期收集某些 AI 服务使用的 Web 数据的爬虫程序,在全球前 1000 个顶级网站上被屏蔽率为 6.77%。
任何您可以从 Web 浏览器访问的页面都可以被爬虫程序「抓取」,它们就像浏览器一样运行,但将材料存储在数据库中而不是向用户显示。
这就是搜索引擎如 Google 收集信息的方式。网站所有者一直有能力发布指令,告诉这些爬虫程序离开他们的网站,但合作完全是自愿性质,并且恶意操作者可以忽略这些指令。
谷歌和其他网络公司认为其数据爬虫工作属于合理使用范围,但许多出版商和知识产权持有人长期以来一直反对此做法,并且该公司因此面临了多起诉讼。大型语言模型和生成式 AI 的兴起使得这个问题重新受到关注,因为 AI 公司派出自己的爬虫程序收集数据以培训其模型并提供聊天机器人所需素材。
自从 Google 和其他搜索网站将用户引导至其支持广告的网站后,一些出版商至少认为允许搜索爬虫程序进入其网站具有某种价值。然而,在 AI 时代中,出版商更积极地阻止爬虫程序进入其网站,因为暂时没有将其数据交给 AI 公司的好处。许多媒体公司目前正在与 AI 公司就以费用向其授权数据进行谈判,但这些谈判还处于早期阶段。
在过去 20 年中被 Google 拿走了一些东西的媒体机构对 OpenAI 等快速商业化的 AI 服务持敌意和「我们不会再上当」的态度。据 The Information 报道,OpenAI 预计在未来一年内将带来超过 10 亿美元的收入。
新闻媒体公司正在努力找到平衡点,在接受和抵制人工智能之间挣扎。一方面,该行业迫切需要寻找创新方法来提高劳动密集型业务的利润率。
另一方面,在人们对新闻媒体公司的信任度处于历史低点之际,将人工智能引入新闻编辑室的工作流程,会带来具有挑战性的道德问题。
而如果太多的网络阻碍人工智能爬虫,它们的所有者可能会发现更难改进和更新他们的人工智能产品——而且好的数据也变得越来越难找到。
Originality.AI 的发现显示,前 1000 个网站中 GPTBot 的屏蔽率每周增加约 5%。
国产大模型落地,等一个“Sora时刻”
仅凭几十个提示词,就能生成一段流畅完整、视角多元的视频,其内容质量几乎能以假乱真,甚至不亚于专业拍摄团队,这就是OpenAI首款文生视频产品Sora,一经发布便激起千层浪,让全球感受到新的AI震撼。2024年的AI故事,伴随着这款杀手级应用的横空出世拉开帷幕,Sora再度让所有人注意到了AI的无限可能性,为略显疲软的市场再打了一针鸡血。0001恒大汽车获中东资本5亿美元战略投资
8月14日,恒大汽车发布公告,获得总部位于阿联酋迪拜的纽顿集团约5亿美元战略投资。恒大汽车表示,此次牵手中东资本,将有效解决恒大汽车发展面临的资金难题。恒大汽车将凭借先进的技术积累、智能化的制造基地、过硬的产品品质以及全球化的供应链体系,全力推进恒驰5生产销售,迅速占领市场,并进一步推进恒驰6、恒驰7等新车型的研发及量产。站长网2023-08-15 08:28:550000三星折叠屏新机已支持系统级地震预警 S24后续将推送
三星ZFold6和ZFlip6折叠屏新机即将进行功能升级,增加地震预警功能。此次升级由成都高新减灾研究所提供技术支持,覆盖31个省/直辖市/自治区。用户可以设置低烈度地震级别阈值以避免干扰,并在锁屏界面上显示紧急联系人信息、医疗信息等功能,确保在发生地震时能够及时采取避难措施或寻求帮助。除了ZFold6和ZFlip6外,该功能也会推送到S24系列等其他三星机型上。站长网2024-07-13 23:34:020000首个开源中文金融大模型来了!解释授信额度、计算收益率、决策参考样样通,来自度小满|附下载
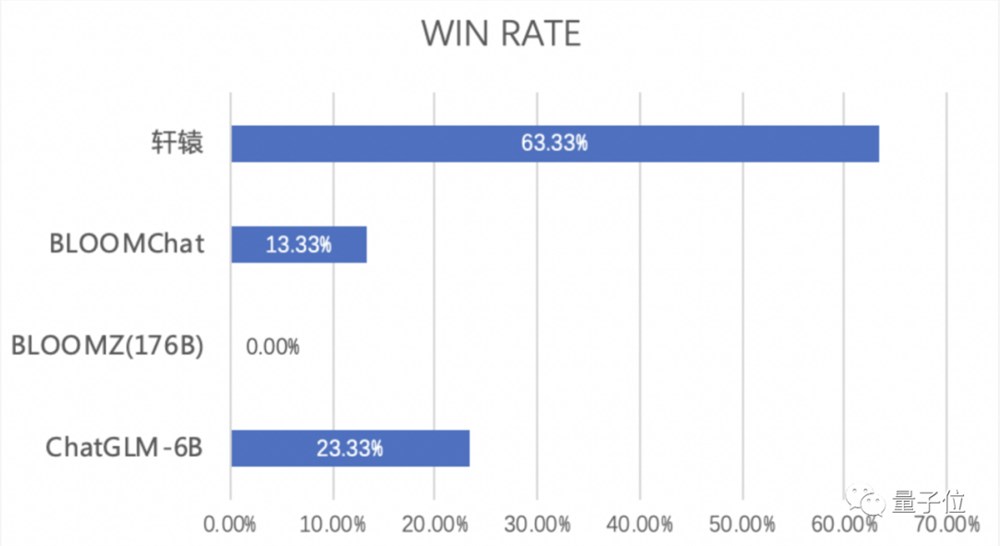
金融行业正迎来大模型时代。近日,度小满正式发布千亿级中文对话大模型轩辕,集中文、金融、开源特色于一身。基于BLOOM-176B研发的轩辕大模型,在金融场景中的任务评测中,效果相较于通用大模型大幅提升,表现出明显的金融领域优势。站长网2023-05-27 14:48:320000AI日报:字节推王炸级语音生成模型Seed-TTS;Suno新功能被Udio抢跑;腾讯发布开源混元DiT加速库;即梦全量上线实时画布功能
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/1、字节推语音生成模型Seed-TTS擅长感情控制,声音与真人无异站长网2024-06-06 21:07:540000