想让大模型在prompt中学习更多示例,这种方法能让你输入更多字符
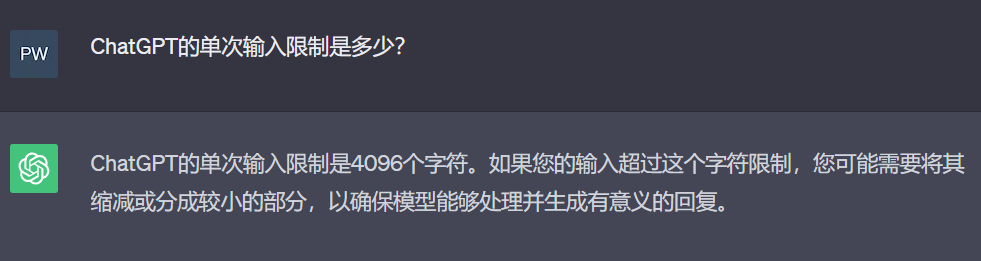
我们知道在使用 GPT 和 LLaMA 等大型语言模型时,输入的 prompt 存在字符数限制,比如 ChatGPT 目前的输入字符限制是4096个字符。这会限制上下文学习和思维链等技术的发挥空间,毕竟用户只能提供有限的示例数量。近日,Nous Research、EleutherAI 和日内瓦大学的一个研究团队提出了一种扩展上下文窗口的方案 YaRN ,并在实验中取得了优于其它所有方法的效果,而且他们还发布了使用 YaRN 微调过的 LLaMA27B/13B 模型,其上下文窗口为64k 和128k。
基于 Transformer 的大型语言模型(LLM)已经展现出执行上下文学习(ICL)的强大能力,并且几乎已经成为许多自然语言处理(NLP)任务的不二选择。Transformer 的自注意力机制可让训练高度并行化,从而能以分布式的方式处理长序列。LLM 训练所用的序列的长度被称为其上下文窗口。
Transformer 的上下文窗口直接决定了可以提供示例的空间量,从而限制了其 ICL 能力。
如果模型的上下文窗口有限,那么为模型提供稳健示例的空间就更少,而这些稳健示例正是执行 ICL 所用的。此外,当模型的上下文窗口特别短时,摘要等其它任务也会受到严重妨碍。
就语言本身的性质来说,token 的位置对有效建模来说至关重要,而自注意力由于其并行性,并不会直接编码位置信息。Transformer 架构引入了位置编码来解决这个问题。
原始的 Transformer 架构使用了一种绝对正弦位置编码,之后其被改进成了一种可学习的绝对位置编码。自那以后,相对位置编码方案又进一步提升了 Transformer 的性能。目前,最流行的相对位置编码是 T5Relative Bias、RoPE、XPos 和 ALiBi。
位置编码有一个反复出现的限制:无法泛化在训练期间看到的上下文窗口。尽管 ALiBi 等一些方法有能力做一些有限的泛化,但还没有方法能泛化用于显著长于其预训练长度的序列。
已经出现了一些试图克服这些限制的研究成果。比如,有研究提出通过位置插值(PI)来稍微修改 RoPE 并在少量数据上微调来扩展上下文长度。
两个月前,Nous Research 的 Bowen Peng 在 Reddit 分享了一种解决思路,即通过纳入高频损失来实现「NTK 感知型插值」。这里的 NTK 是指 Neural Tangent Kernel(神经正切核)。

其声称经过 NTK 感知型扩展的 RoPE 能让 LLaMA 模型的上下文窗口大幅扩展(超过8k),同时还无需任何微调,对困惑度造成的影响也极小。
近日,他与另外三位合作者的相关论文出炉了!

论文:https://arxiv.org/abs/2309.00071
模型:https://github.com/jquesnelle/yarn
在这篇论文中,他们对 NTK 感知型插值做出了两点改进,它们分别侧重于不同的方面:
动态 NTK 插值法,无需微调就能用于预训练模型。
部分 NTK 插值法,当使用少量更长上下文的数据微调后,模型能取得最佳表现。
研究者表示,在这篇论文诞生前,就已经有研究者将 NTK 感知型插值和动态 NTK 插值用于一些开源模型。比如 Code Llama(使用 NTK 感知型插值)和 Qwen7B(使用动态 NTK 插值)。
在这篇论文中,基于之前有关 NTK 感知型插值、动态 NTK 插值和部分 NTK 插值的研究成果,研究者提出了 YaRN(Yet another RoPE extensioN method),一种可以高效扩展使用旋转位置嵌入(Rotary Position Embeddings / RoPE)的模型的上下文窗口的方法,可用于 LLaMA、GPT-NeoX 和 PaLM 系列模型。研究发现,只需使用原模型预训练数据规模大约0.1% 量的代表性样本进行微调,YaRN 就能实现当前最佳的上下文窗口扩展性能。
方法
旋转位置嵌入(Rotary Position Embeddings / RoPE)最早由论文《RoFormer: Enhanced transformer with rotary position embedding》引入,也是 YaRN 的基础。
简单来说,RoPE 可以写成如下形式:
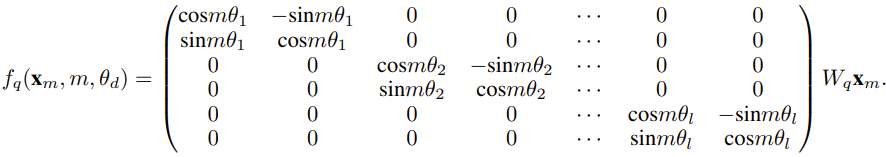
对于使用固定上下文长度预训练的 LLM,如果使用位置插值(PI)来扩展上下文长度,则可以表示为:
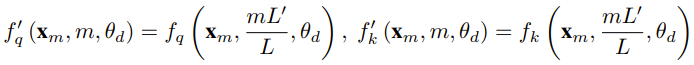
可以看出 PI 对所有 RoPE 维度都会做同等延展。研究者发现 PI 论文中描述的理论插值界限不足以预测 RoPE 和 LLM 内部嵌入之间的复杂动态。下面将描述研究者发现并解决的 PI 的主要问题,以便读者了解 YaRN 中各种新方法的背景、起因和解决理由。
高频信息丢失 ——NTK 感知型插值
如果只从信息编码的角度看 RoPE,根据神经正切核(NTK)理论,如果输入维度较低且对应的嵌入缺乏高频分量,那么深度神经网络难以学习高频信息。
为了解决在对 RoPE 嵌入插值时丢失高频信息的问题,Bowen Peng 在上述 Reddit 帖子中提出了 NTK 感知型插值。这种方法不会对 RoPE 的每个维度进行同等扩展,而是通过更少地扩展高频和更多地扩展低频来将插值压力分散到多个维度。
在测试中,研究者发现在扩展未经微调的模型的上下文大小方面,这种方法优于 PI。但是,这种方法有一个重大缺点:由于它不只是一种插值方案,某些维度会被外推入一些「界外」值,因此使用 NTK 感知型插值进行微调的效果不及 PI。
更进一步说,由于存在「界外」值,理论上的扩展因子就无法准确地描述真实的上下文扩展程度。在实践中,对于给定的上下文长度扩展,必须将扩展值 s 设置得比期望的扩展值高一点。
相对局部距离的损失 —— 部分 NTK 插值
对于 RoPE 嵌入,有一个有趣的观察:给定一个上下文大小 L,存在某些维度 d,其中的波长 λ 长于预训练阶段见过的最大上下文长度(λ > L),这说明某些维度的嵌入可能在旋转域中的分布不均匀。
PI 和 NTK 感知型插值会平等地对待所有 RoPE 隐藏维度(就好像它们对网络有同样的效果)。但研究者通过实验发现,网络会给某些维度不同于其它维度的待遇。如前所述,给定上下文长度 L,某些维度的波长 λ 大于或等于 L。由于当一个隐藏维度的波长大于或等于 L 时,所有的位置配对会编码一个特定的距离,因此研究者猜想其中的绝对位置信息得到了保留;而当波长较短时,网络仅可获得相对位置信息。
当使用扩展比例 s 或基础变化值 b' 来拉伸所有 RoPE 维度时,所有 token 都会变得与彼此更接近,因为被一个较小量旋转过的两个向量的点积会更大。这种扩展会严重损害 LLM 理解其内部嵌入之间小的局部关系的能力。研究者猜测这种压缩会导致模型对附近 token 的位置顺序感到困惑,从而损害模型的能力。
为了解决这个问题,基于研究者观察到的现象,他们选择完全不对更高频率的维度进行插值。
他们还提出,对于所有维度 d,r < α 的维度按扩展度 s 线性插值(与 PI 一样,避免出现外推);r > β 的维度就完全不插值(总是外推)。
使用这一小节描述的技术,一种名为部分 NTK 插值的方法诞生了。这种改进版方法优于之前的 PI 和 NTK 感知型插值方法,其适用于无微调和已微调模型。因为该方法避免了对旋转域分布不均匀的维度进行外推,因此就避免了之前方法的所有微调问题。
动态缩放 —— 动态 NTK 插值
当使用 RoPE 插值方法无微调地扩展上下文大小时,我们希望模型在更长的上下文大小上慢慢地劣化,而不是在扩展度 s 超过所需值时在整个上下文大小上完全劣化。
在动态 NTK 方法中,扩展度 s 是动态计算的。
在推理过程中,当上下文大小被超过时,就动态地更改扩展度 s,这样可让所有模型在达到训练的上下文限制 L 时缓慢地劣化而不是突然崩溃式劣化。
增加用于长距离的平均最小余弦相似度 ——YaRN
即便解决了前面描述的局部距离问题,为了避免外推,也必须在阈值 α 处插值更大的距离。直觉来看,这似乎不应该是个问题,因为全局距离无需高精度也能区分 token 位置(即网络只需大概知道 token 是在序列的开头、中间或末尾即可)。
但是,研究者发现:由于平均最小距离随着 token 数量的增加而变得更近,因此它会使注意力 softmax 分布变得更尖(即减少了注意力 softmax 的平均熵)。换句话说,随着长距离衰减的影响因插值而减弱,网络会「更加关注」更多 token。这种分布的转变会导致 LLM 输出质量下降,这是与之前问题无关的另一个问题。
由于当将 RoPE 嵌入插值到更长的上下文大小时,注意力 Softmax 分布中的熵会减少,因此研究者的目标是逆转这种熵减(即增加注意力 logit 的「温度」)。这可以通过在应用 softmax 之前将中间注意力矩阵乘以温度 t >1来完成,但由于 RoPE 嵌入被编码为一个旋转矩阵,就可以简单地按常数因子 √t 来扩展 RoPE 嵌入的长度。这种「长度扩展」技巧让研究可以不必修改注意力代码,这能大幅简化与现有训练和推理流程的集成,并且时间复杂度仅有 O (1)。
由于这种 RoPE 插值方案对 RoPE 维度的插值不均匀,因此很难计算相对于扩展度 s 所需的温度比例 t 的解析解。幸运的是,研究者通过实验发现:通过最小化困惑度,所有 LLaMA 模型都遵循大致相同的拟合曲线:
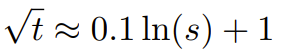
研究者是在 LLaMA7B、13B、33B 和65B 上发现这个公式的。他们发现这个公式也能很好地适用于 LLaMA2模型(7B、13B 和70B),差别很细微。这表明这种熵增特性很常见,可以泛化到不同的模型和训练数据。
这种最终修改方案产出了 YaRN 方法。新方法在已微调和未微调场景中都胜过之前所有方法,而且完全不需要修改推理代码。只需要修改一开始用于生成 RoPE 嵌入的算法。YaRN 如此简单,使其可以在所有推理和训练库中轻松实现,包括与 Flash Attention2的兼容性。
实验
实验表明 YaRN 能成功扩展 LLM 的上下文窗口。此外,他们仅训练了400步就得到了这一结果,这差不多只有模型的原始预训练语料库的0.1%,与之前的研究成果相比有大幅下降。这说明新方法具有很高的计算效率,没有额外的推理成本。
为了评估所得到的模型,研究者计算了长文档的困惑度,并在已有基准上进行了评分,结果发现新方法胜过所有其它上下文窗口扩展方法。
首先,研究者评估了上下文窗口增大时模型的性能表现。表1总结了实验结果。

表2展示了在50个未截断的 GovReport 文档(长度至少为16k token)上的最终困惑度。

为了测试使用上下文扩展时模型性能的劣化情况,研究者使用 Hugging Face Open LLM Leaderboard 套件评估了模型,并将其与 LLaMA2基准模型以及公开可用的 PI 和 NTK 感知型模型的已有分数进行了比较。表3总结了实验结果。

AI机器人“整顿”社交平台
在“今天我要按时下班”的微博下,提醒“明天也要准时上班哦”;在“我过得不幸福”的微博下,安抚道“亲爱的,快乐和幸福是我们自己给自己的”;在“我要改变自己”的微博下,鼓励说“宝宝你很好,不要改变”……站长网2024-03-22 10:03:290000仅靠自学!开发者30分钟制作出「垃圾游戏」:收入超35万美元,下载量超12万次
相信在多数人的印象当中,游戏开发一直是一项既昂贵又耗时的工作:去年5月,外媒InsiderGaming曾透露《GTA6》的开发成本已达10-20亿美元,这个数字比《命运》(5亿)、《星际公民》(5亿)和《赛博朋克2077》(3.3亿)等游戏都要高上不少,大型游戏的成本甚至比电影还高。育碧公司全球18个工作室的2000人正在开发其《刺客信条》系列的下一部作品,具体或将耗时2-3年。站长网2024-02-22 16:39:320000报告:Real Car Driving: Race City 3D位列10月游戏下载榜榜首
SensorTower商店情报数据显示,BotanicaGlobal《RealCarDriving:RaceCity3D》以超过1900万次下载,位列10月全球移动游戏下载榜榜首。印度是该游戏第一大市场,贡献了26.4%的下载量;其次是巴西和墨西哥市场,分别占12%和7%。站长网2023-11-28 15:24:140000Midjoureny网站Alpha版本优化 增加3个分类
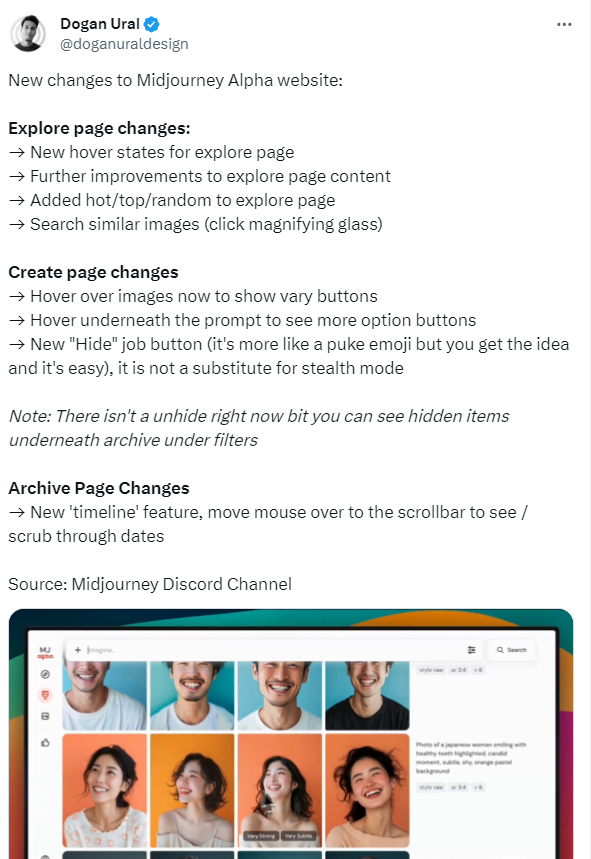
Midjoureny网站的Alpha版本进行了一系列体验优化,主要是对探索页面进行了改进。这次更新主要包括对鼠标悬停效果的丰富化,对页面内容的进一步优化,以及新增了热门、精选和随机浏览选项。此外,还新增了相似图片搜索功能,用户只需点击放大镜图标即可使用。站长网2024-01-25 10:49:480000B站“亮底牌”,靠大开环直播导流打赢双11?
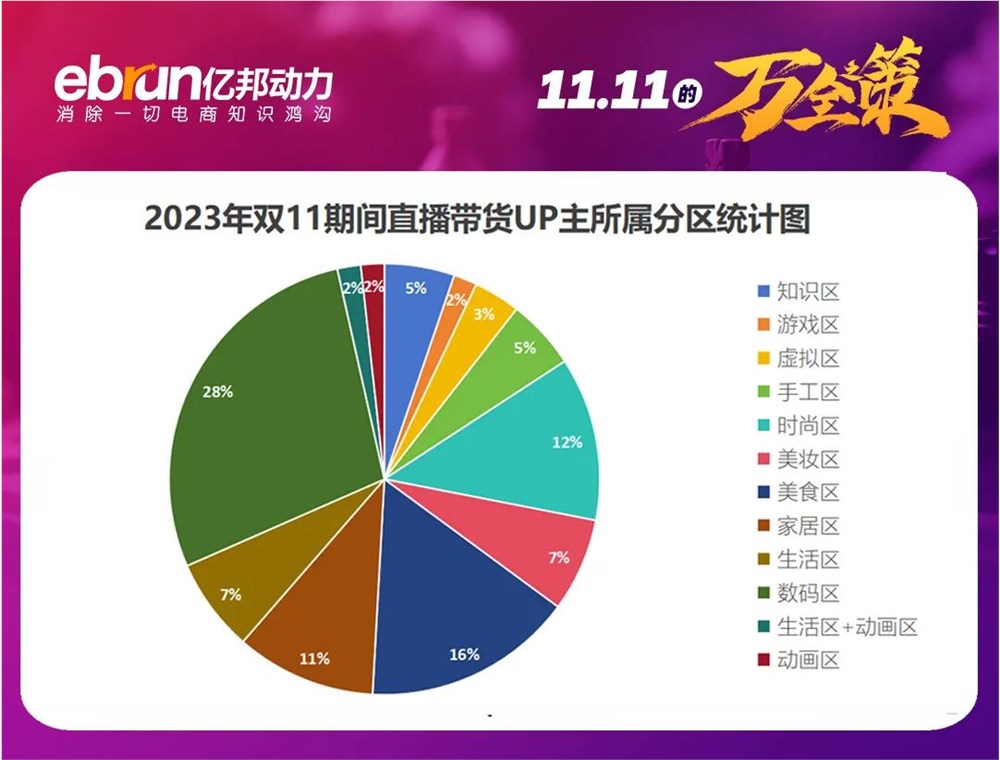
平台血拼低价,双11再起波澜,B站也在暗处悄悄使劲。9月,B站推出直播带货超新星计划,为UP主对接货源,持续开放各品类的招商。一个月后,B站陆续对外发布消息,称双11期间将为电商平台导流。站长网2023-11-06 17:11:470000