华人团队推出Medusa简单框架 可将LLM推理速度提高2倍
站长网2023-09-13 12:00:371阅
来自普林斯顿、UIUC等机构的华人团队提出一个用于加速大型语言模型(LLM)推理速度的简单框架Medusa,并于9月12日开源发布。测试结果显示,Medusa可以将LLM的生成效率提高约2倍。
Medusa是一个简单的框架,它让大家也可以使用多解码头技术来加速大型语言模型的生成。目前,许多热门的加速技术如speculative decoding都存在一些痛点,比如需要一个不错的draft模型作为基础,系统复杂度高,采样生成时效率不高等。
项目地址:https://github.com/FasterDecoding/Medusa
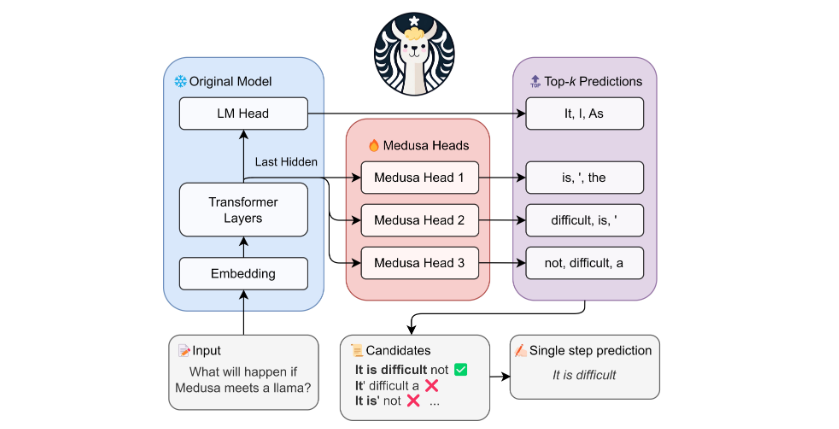
Medusa的方法是在原有的语言模型上增加额外的“解码头”,让每个头同时预测多个可能的未来词元。在使用Medusa增强模型时,原有的模型保持不变,仅新增的解码头在训练中进行微调。生成时,这些头并行产生多个可能的词,然后通过一种基于树的attention机制合并处理,最后使用一般的采纳策略从候选中挑选出最长的可信前缀进行解码。
研究人员通过以下几点设计,来解决speculative decoding存在的问题:
1) 不引入新的模型,仅在原模型上新增解码头,训练时参数效率高。
2) 生成时不需要严格匹配原模型的分布,使非贪婪生成甚至比贪婪解码还快。
第一个版本主要优化了每个batch只有一个样例的场景,也就是本地机器上常见的使用方式。在这种配置下,Medusa可以为Vicuna系列模型带来约2倍的加速。研究人员称正在积极扩展Medusa的应用场景,集成到更多的推理框架中,以获得更高的性能提升。
Medusa核心功能:
- 在现有语言模型上增加多解码头
- 高效训练参数
- 生成时树形attention机制合并多个预测
- 非贪婪生成模式下实现更快速度
0001
评论列表
共(0)条相关推荐
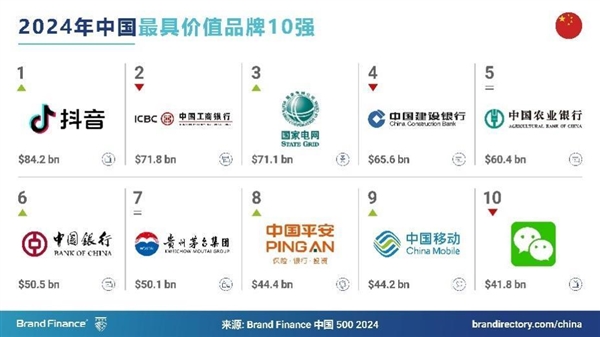
2024年中国品牌价值500强发布:抖音首登榜首
今日,备受瞩目的《BrandFinance2024年中国品牌价值500强》报告终于揭晓,这份报告深入剖析了国内各行业的品牌实力与价值。在众多知名品牌中,抖音凭借其卓越的品牌价值和增长势头,成功脱颖而出,成为本年度中国最具价值的品牌。站长网2024-05-09 16:45:220000微软Xbox拥抱AI 走量内卷加剧
游戏AI内卷又迎来新的大玩家,微软发布公告称与InworldAI公司建立合作关系,将生成式AI模型的强大功能带入游戏开发。近两年,游戏行业AIGC进击的消息蔚然成风。无论是公开财报还是演讲发声,AI与行业、公司、产品结合成为无法回避的环节,市场、企业、资本包括股民都聚焦于此。站长网2023-11-09 15:54:380001英国顶尖大学就如何应对生成式人工智能达成协议:承诺将道德使用 AI 纳入教学和评估中
一个由英国顶尖大学组成的联盟近日签署了一系列关于道德使用生成人工智能(AI)的指导原则,以应对学术界越来越普遍使用该技术的情况。包括牛津大学、伦敦经济学院、剑桥大学和伦敦帝国理工学院在内的所有24所罗素集团大学的校长设计了五项指导原则(pdf),以推动人工智能在课堂和教学中的使用。罗素集团成立于1994年,由二十四间英国的研究型大学所组成其性质类似于美洲大学协会。站长网2023-07-05 18:20:160000跟安卓玩法一样了!苹果允许iPhone用户从网站下载App
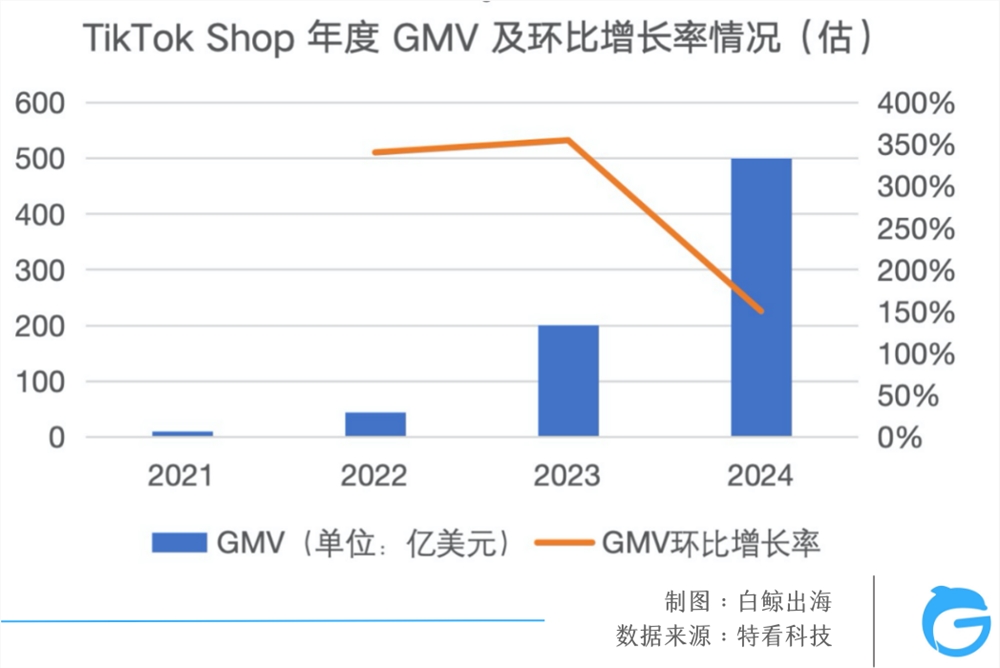
快科技3月13日消息,上周苹果推送了iOS17.4正式版,允许欧盟用户通过第三方应用商店下载安装应用程序,俗称侧载”。不止于此,针对欧盟用户,苹果进一步调整了侧载功能,用户不仅可以从第三方应用商店下载应用,还可以从网站下载安装应用,这意味着iOS在欧盟的侧载方式跟安卓完全一样了。苹果方面确认,这项调整会在今年春季晚些时候上线,届时欧盟用户不需要依赖应用商店就能安装应用。站长网2024-03-13 11:51:4600057TikTok电商大盘三位数增长,为什么赚钱的不是我?
站长网2024-02-07 16:03:410002