Nvidia公布新文本转视频模型
Nvidia公布新文本转视频模型 基于Stable Diffusion开发!
Nvidia公布了其基于StableDiffusion模型开发的文本转视频模型——NvidiaVideoLDM。Nvidia通过对现有模型的微调,大大减少了生成视频的过程和时间。该模型增加了一个时间维度,可以在多个帧上实现时间对齐的图像合成。该团队训练了一个视频模型,以512x1024像素的分辨率生成几分钟的汽车行驶视频,在大多数基准测试中达到SOTA。站长网2023-04-20 14:28:430002


热点
抖音、小红书“反精致”崛起,为何粗糙真实更得人心?
2025-02-12 10:27:31赢下精品短剧春节档,腾讯视频靠“战略纵深”
2025-02-13 18:00:17接入了DeepSeek后的飞书,强大到我有点陌生。
2025-02-12 18:12:58商业导师们全面拥抱DeepSeek
2025-02-12 17:41:51欢迎来到,短剧的“细糠时代”?
2025-02-12 15:20:18千亿美元收购,马斯克是给OpenAI送财还是送灾?
2025-02-12 15:07:25千万网红鼻祖开播,一小时狂卖5000多单,只赚26元?
2025-02-12 15:05:09DeepSeek算力卡脖子,高校AI研究遇瓶颈?华为联合15校给出最强解法
2025-02-12 13:56:21作业帮“制霸”全球,头部语言产品吸金能力堪比中重度游戏
2025-02-12 09:29:33我的媒介漂流十年——在AI出现以前
2025-02-12 09:15:11
关注
AI产品数据对比:一分没花的DeepSeek一骑绝尘,Kimi六小龙花钱还受伤
2025-02-10 08:41:45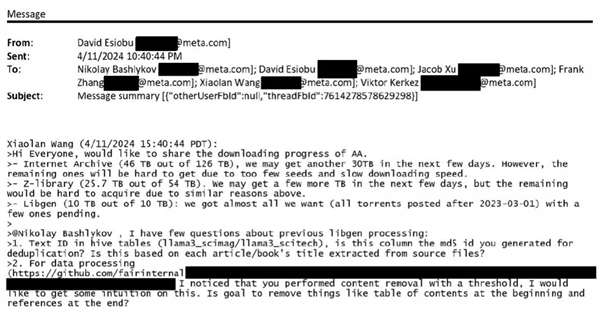
为训练AI不择手段!Meta被曝下载数十TB盗版电子书
2025-02-10 08:38:57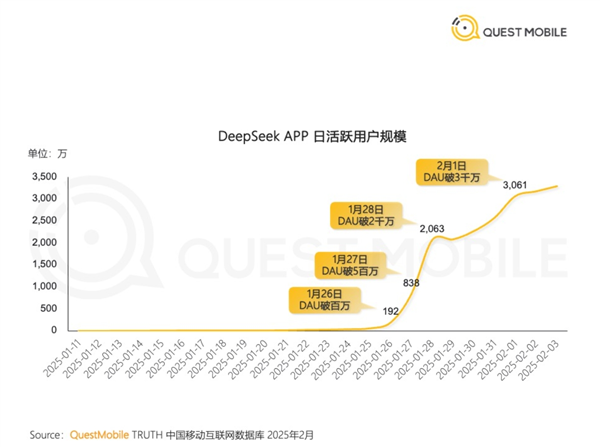
中国AI新秀爆火 DeepSeek成史上最快突破3000万日活App
2025-02-10 08:38:56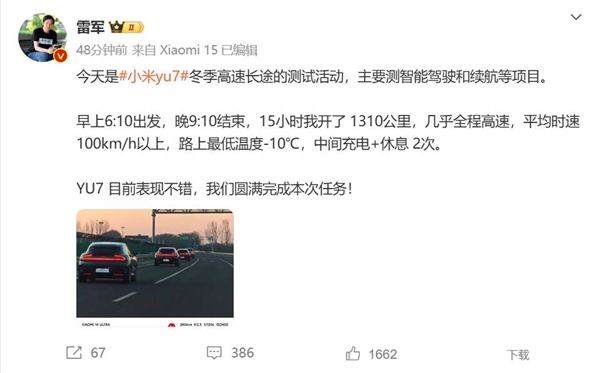
雷军驾驶小米YU7参与冬测:表现不错 测试任务圆满完成
2025-02-10 05:11:19
用DeepSeek“赚钱”网课泛滥 专家:普通用户不用花钱学
2025-02-10 05:11:18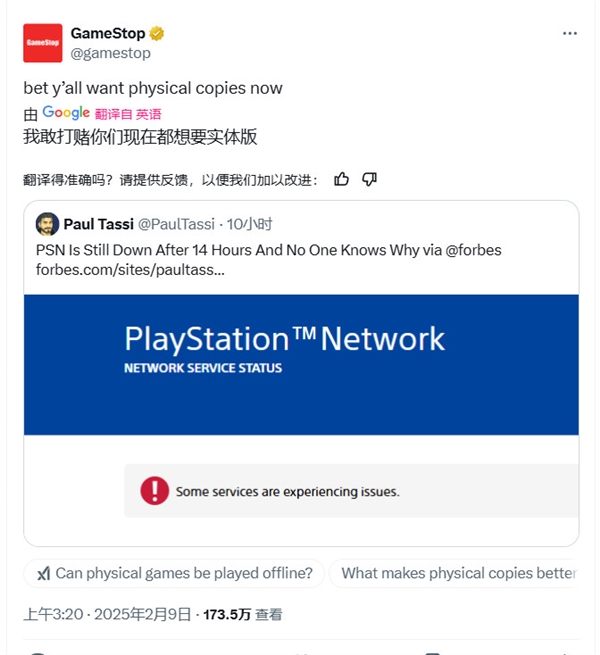
索尼PSN严重宕机!超过24小时才恢复:实体游戏零售商在线补刀
2025-02-10 05:11:17京东外卖“低佣”入局,美团回应“30%高佣”质疑
2025-02-10 05:11:12|美团开放个人摄影师入驻,搅热500亿市场?
2025-02-10 03:41:55《哪吒2》改写中国影史背后,这些配角燃爆了社交媒体
2025-02-10 03:21:53
DeepSeek下棋靠忽悠赢了ChatGPT,网友:孙子兵法都用上了
2025-02-10 03:17:44

