Kandinsky1:3.3亿参数强大模型,文本生成逼真图像
划重点:
1. 🌟 Kandinsky1:3.3亿参数的强大模型,以令人瞩目的图像生成质量表现
2. 🖼️ 文本到图像生成模型的演进,潜在扩散技术的引入
3. 📊 Kandinsky在COCO-30K验证数据集上取得8.03的FID分数,与最先进的文本到图像生成模型竞争激烈
最近几年,计算机视觉和生成建模领域取得了显著进展,推动了文本到图像生成的不断发展。各种生成架构,包括基于扩散的模型,在提高生成图像的质量和多样性方面发挥了关键作用。Kandinsky是一个拥有3.3亿参数的强大模型,并突出了它在可度量的图像生成质量方面的卓越表现。
文本到图像生成模型已经从具有内容级别工件的自回归方法演化到了基于扩散的模型,如DALL-E2和Imagen。这些扩散模型被归类为像素级和潜在级,它们在图像生成方面表现出色,超越了GANs在保真度和多样性方面的表现。它们无需敌对训练就能集成文本条件,这一事实由GLIDE和eDiff-I等模型所证明,它们生成低分辨率图像并使用超分辨率扩散模型进行升采样。这些进步已经改变了文本到图像生成的方式。
AIRI、Skoltech和Sber AI的研究人员引入了Kandinsky,这是一种结合了潜在扩散技术和图像先验模型的新型文本到图像生成模型。Kandinsky采用了改进的MoVQ实现作为其图像自动编码器组件,并单独训练图像先验模型,将文本嵌入映射到CLIP的图像嵌入。他们的方法提供了一个用户友好的演示系统,支持多样的生成模式,并发布了模型的源代码和检查点。

他们的方法引入了一种潜在扩散架构,用于文本到图像合成,利用了图像先验模型和潜在扩散技术。它采用了一种图像先验方法,将文本和图像嵌入之间的扩散和线性映射结合起来,使用CLIP和XLMR文本嵌入。他们的模型包括三个关键步骤:文本编码、嵌入映射(图像先验)和潜在扩散。基于完整数据集统计的视觉嵌入的逐元归一化实施,加速了扩散过程的收敛。
Kandinsky架构在文本到图像生成方面表现出色,以256×256的分辨率在COCO-30K验证数据集上获得了8.03的令人印象深刻的FID分数。线性先验配置产生了最佳的FID分数,表明视觉和文本嵌入之间存在潜在的线性关系。他们的模型的能力由在一组猫图像上训练“猫先验”而得到的图像生成成绩得以证明。总的来说,Kandinsky在文本到图像合成方面与最先进的模型竞争激烈。
Kandinsky是一种基于潜在扩散的系统,在图像生成和处理任务中表现出色。他们的研究广泛探讨了图像先验设计选择,线性先验显示出潜在的潜在线性关系。用户友好的界面,如Web应用程序和Telegram机器人,有助于提高可访问性。
未来的研究方向包括利用先进的图像编码器、改进UNet架构、改进文本提示、生成更高分辨率的图像,以及探索本地编辑和基于物理的控制等功能。研究人员强调了解决内容问题的需求,建议采取实时监管或强大的分类器来减轻不良输出。
论文网址:https://arxiv.org/abs/2310.03502
项目网址:https://github.com/ai-forever/Kandinsky-2
江西新首富,踩着英伟达,狂赚700亿
2015年,北京科学院南路6号。几个年轻人,挤在一间小黑屋里,紧张地测试着一款芯片。当电脑屏幕上跳出测试结果正确时,他们再也抑制不住激动:这意味着,世界上第一款人工智能芯片,就要诞生了!图源备注:图片由AI生成,图片授权服务商Midjourney不再是跟随超越谷歌、亚马逊,碾压英特尔。00002024年结束,哪里是原创动画的应许之地?
2024年即将落幕,这一年国产动画市场逐渐呈现出清晰且多元的态势。视频平台依旧是动画行业的重要力量,各家平台有的以“爽文漫”吸引观众,有的深耕“新国风”赛道,有的依靠大IP与大制作,在异能和科幻题材中持续发力。市场上IP改编作品依旧是主流。行业早早就有了共识,依靠IP,动画作品成功率相对稳定,原著受众作底,动画视听吸引新观众,最终圈层融合实现商业变现。站长网2024-12-23 14:19:380000天涨粉314万,泼天流量砸中“草根网红”郭有才
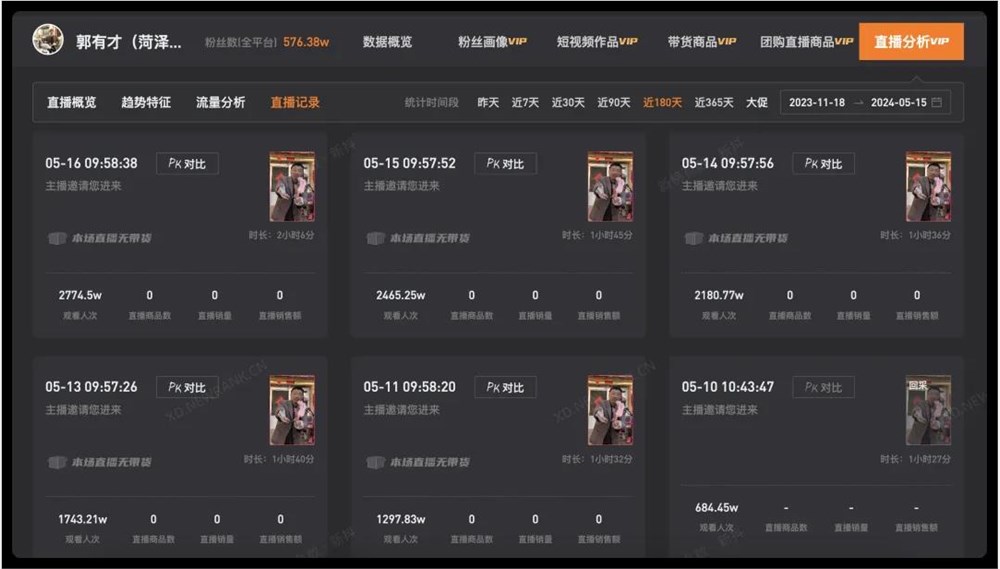
一首《诺言》全网刷屏,郭有才爆红出圈。郭有才-菏泽树哥,赞7621他梳着上世纪90年代流行的大背头,戴一副银丝框眼镜,身着复古风格的宽大西装,打着一条红白条纹领带,手上戴着副黑色皮手套,在直播间里声嘶力竭地唱着这首老歌:我不了解天长地久,要用这么多的寂寞来等是你让我的心痛,一天比一天深无奈人在风里、人在雨里、人在爱的岁月里漂流你我不能重头、不能停留、不能抗拒命运左右……站长网2024-05-17 17:50:120003Kimi Chat移动端UI大幅重构 并上线“月之亮面”模式
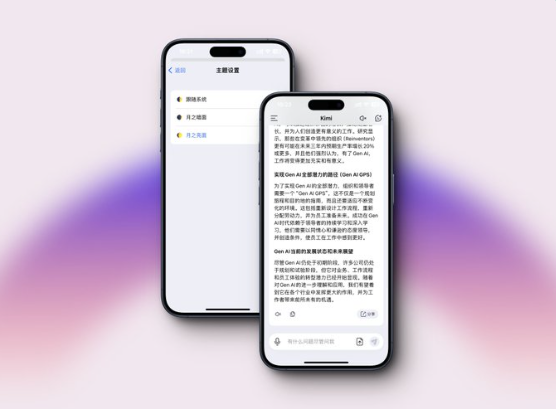
KimiChat移动端应用迎来了重要的更新,版本1.2.1对用户界面(UI)进行了全面的重构,并引入了“月之亮面”浅色模式,旨在提供更加舒适和直观的用户体验。更新亮点包括:用户界面(UI)改进:界面经过重新设计,提升了美观度和易用性,使用户操作更加直观。性能优化:响应速度和流畅度得到提升,减少了应用运行中的卡顿和延迟。站长网2024-04-28 20:50:040000Meta开源最新模型——Llama Guard-7b
全球社交、科技巨头Meta在官网开源了全新模型——LlamaGuard。据悉,LlamaGuard是一个基于Llama2-7b的输入、输出保护模型,可对人机会话过程中的提问和回复进行分类,以判断其是否存在风险。可与Llama2等模型一起使用,极大提升其安全性。0002