Google的E3 TTS 通过扩散模型提供高质量音频合成方法
要点:
1、E3TTS 是一种简化高效的端到端扩散式文本到语音模型,通过扩散模型生成高保真的语音波形。
2、E3TTS 模型由预训练的 BERT 模型和扩散 UNet 模型组成,以提取文本信息并迭代地生成最终的语音波形。
3、E3TTS 不仅能生成高保真音频,还支持零样本任务,如语音编辑和基于提示的生成。
Google 的研究团队提出了一种名为 E3TTS 的简便端到端扩散式文本到语音模型。该模型通过扩散模型保留时间结构,能够直接接受纯文本输入并生成音频波形。它利用预训练的 BERT 模型提取文本信息,并通过扩散 UNet 模型迭代地生成最终的语音波形。相比其他现有的文本到语音系统,E3TTS 简化了部署、训练和设置过程,并且不依赖中间特征的质量。
E3TTS 模型采用非自回归方式,以文本作为输入,实时生成音频波形。它的架构包括两个主要模块:预训练的 BERT 模型用于提取输入文本的相关信息,扩散 UNet 模型用于处理 BERT 输出,迭代地优化初始噪声波形以预测最终的原始波形。这种设计使得 E3TTS 能够直接从 BERT 特征生成高质量的音频波形,并且可以使用多种语言进行训练。
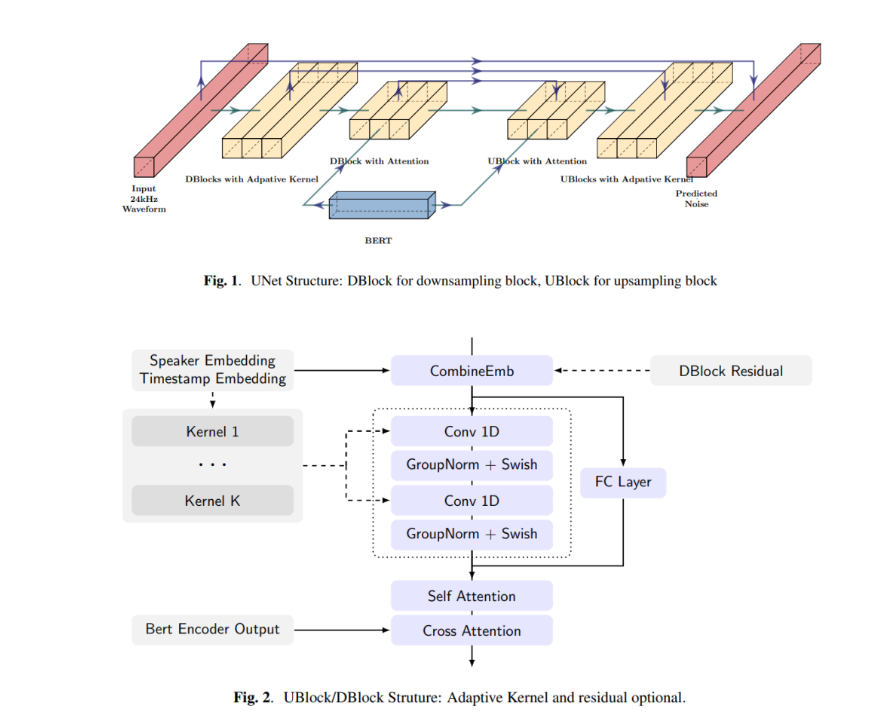
为了增强对 BERT 输出的信息提取,E3TTS 模型采用了 U-Net 结构,其中包含一系列下采样和上采样块。在顶层的下采样 / 上采样块中,引入了交叉注意力机制。在较低层次的块中,使用了自适应 softmax 卷积神经网络(CNN)内核,其内核大小由时间步和说话者确定。在其他层次中,通过特征级线性调制(FiLM)将说话者和时间步嵌入进行组合,包括用于通道级缩放和偏差预测的复合层。
实验证明,E3TTS 能够生成高保真音频,接近最先进的神经 TTS 系统的性能。此外,它还支持各种零样本任务,如语音编辑和基于提示的生成。E3TTS 的设计简化了端到端 TTS 系统的构建,并在实验中取得了令人印象深刻的结果。
总结起来,E3TTS 通过扩散模型从 BERT 特征直接生成高质量音频。它简化了端到端 TTS 系统的设计,经过实验证明具有出色的性能。
美国参议院提交《安全人工智能法案》旨在建立违规行为数据库
参议院近日提交了一项新法案,旨在通过强制创建记录所有人工智能系统违规行为的数据库来跟踪安全问题。该法案由参议员马克·华纳(D-VA)和汤姆·蒂利斯(ThomTillis)(北卡罗来纳州)提出,名为《安全人工智能法案》。根据该法案,将在国家安全局建立人工智能安全中心,领导“反人工智能”研究并制定防止反人工智能措施的指南。0000商汤科技与上海联通合作 打造世界级AI人工智能产业集群
11月28日,商汤科技与上海联通签署战略合作框架协议,共同打造世界级人工智能产业集群。根据协议,双方将深入贯彻国家发展新一代人工智能的战略部署,发挥各自优势,加快打造世界级人工智能产业集群,营造通用人工智能创新生态,为大模型时代下的人工智能产业发展蓄势储能,共同以全方位、多领域、一体化的合作姿态助力打造上海人工智能主阵地,推动数字经济高质量发展。0000公众号【内容助推】内测,流量来了!
各位村民好,我是村长前几天刚说完,公众号可以修改已发布文章的标题了。公众号标题可以修改了!还有这8个变化。没想到公众号还偷偷隐藏了一个新功能,就是允许账号付费推广自己发布的文章了,这对于内容创作者来说也是一个好消息。01内容助推上线啦!公众号内测的这个功能叫——内容助推,就是允许创作者选择自己发布过的文章,进行投流,类似dou。而这个功能,在视频号上早就上线了,叫视频加热。站长网2024-07-18 17:05:300000辰东新作首订近10万,网文订阅的天花板在哪?
老牌大神再出手。10月24日,零点刚过,分针划过两圈,一本名叫《夜无疆》的网络小说迎来了它的最新一章。几乎是一瞬间,评论区就热闹起来。接着,该章节的订阅人数以迅猛势头增长,不到15分钟的工夫便突破了“万订”大关。至此,这部以永夜为背景展开的东方玄幻网文,正式开启了属于它的“首订”之战。0000科技界“教父”表示:对AI公司造成的伤害必须追究责任
划重点:1.两位“科技教父”,警告强大的人工智能系统威胁社会稳定,要求AI公司对其产品造成的危害负有责任。2.他们强调,在进行更强大的人工智能系统开发之前,应首先了解如何确保其安全。3.政策建议包括政府将三分之一的AI研发资金分配给安全和道德使用。站长网2023-10-24 22:56:510000