Vectara排行榜:OpenAI的GPT-4在文档摘要中幻觉率最低
**划重点:**
1. 📊 Vectara的排行榜显示,OpenAI的GPT-4在文档摘要中具有最低的幻觉率,准确率为97%。
2. 🚀 GPT-4和GPT-4Turbo表现最佳,GPT-3.5Turbo排名第二,Meta Llama为最高得分的非OpenAI模型,而Google Palm排名最后。
3. 🛠 Vectara发布了开源模型,允许任何人检查其大型语言模型的幻觉率,以提高生成式AI系统的可信度。
在一项由Vectara进行的开源模型评估中,OpenAI的GPT-4在文档摘要中表现卓越,凭借其出色的97%准确率和令人瞩目的3%的幻觉率,成为幻觉率最低的大型语言模型。
Vectara在GitHub上发布了一个排行榜,评估了一些大型语言模型在其“Hallucination Evaluation Model”上的表现,该模型衡量了语言模型在摘要文档时引入幻觉的频率。
排名第一的是GPT-4和GPT-4Turbo,它们分别以97%的准确率和3%的幻觉率脱颖而出。另一款OpenAI模型,GPT-3.5Turbo,排名第二,其准确率为96.5%,幻觉率为3.5%。
在非OpenAI模型中,最高得分的是Meta的Llama2,具有70亿参数,准确率达到94.9%,幻觉率仅为5.1%。
然而,谷歌的模型表现相对较差,Google Palm2的准确率为87.9%,幻觉率为12.1%。Palm的聊天优化版本表现更差,准确率仅为72.8%,幻觉率则高达27.2%。
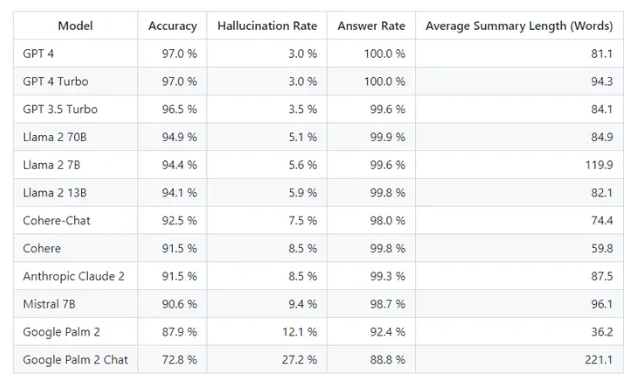
在摘要长度方面,Google Palm2Chat生成的平均摘要字数最高,达到惊人的221个字。相比之下,GPT-4仅生成每个摘要81个字。
Vectara是一家总部位于Palo Alto的公司,他们通过使用开源数据集培训了一个模型,以检测大型语言模型输出中的幻觉。该公司通过其公共API向每个模型提供了1000个短文档,并要求它们仅使用文档中呈现的事实进行摘要。
在这1000个文档中,只有831个被每个模型摘要,其余的文档由于内容限制被至少一个模型拒绝。Vectara随后计算了每个模型的总体准确率和幻觉率。
Vectara的“Hallucination Evaluation Model”是开源的,意味着企业可以使用它来评估其大型语言模型在检索增强生成(RAG)系统中的可信度。用户可以通过Hugging Face访问该模型,并根据自己的需求进行调整。
项目网址:https://huggingface.co/vectara/hallucination_evaluation_model
Shane Connelly,Vectara的产品负责人在博客中写道:“幻觉的风险阻碍了许多企业采用生成式AI。我们的目标是通过量化分析为企业提供他们需要的信息,使他们能够通过有信心地启用生成系统。”
Meta 负责领导自研人工智能芯片的高管将于月底离职
据两位知情人士透露,负责Meta公司研发人工智能芯片工作的高管AlexisBlackBjorlin将于月底离职。AlexisBlackBjorlin曾在芯片公司博通和英特尔工作多年,领导了一个团队设计一款定制芯片,能够处理多种人工智能工作,这是该公司致力于为聊天机器人和图像生成器等产品改造其庞大的数据中心的关键部分。其中一位知情人士表示,她将于月底离职,但不会立即离开公司。站长网2023-09-29 09:34:210000大模型太卷,AI应用就好做吗?
2022年底,ChatGPT推出后迅速在社交媒体上走红,很快,月活用户突破1亿,成为史上增长最快的消费者应用。不久后,国内也掀起了一场轰轰烈烈的大模型竞赛,下场的企业越来越多,都在扬言要赶超ChatGPT。一年过去,大模型没让参赛者看到盈利的曙光,资本市场也在变冷,弄潮儿们发现:AI应用或许比大模型更有机会。站长网2023-12-07 15:58:040001人工智能安全研究公司 CEO 称 Rishi Sunak 的全球 AI 安全峰会可能收效甚微
一位受邀参加下个月RishiSunak国际人工智能安全峰会的高管警告说,这次会议可能收效甚微,并指责强大的科技公司试图「操纵」这场具有里程碑意义的会议。人工智能安全研究公司Conjecture的首席执行官ConnorLeahy表示,他相信政府首脑准备同意一种监管方式,允许企业继续开发「上帝般」的人工智能,几乎不受限制。站长网2023-10-24 21:25:070000微软新的漏洞悬赏计划重点关注人工智能驱动的 Bing
站长之家(ChinaZ.com)10月13日消息:微软宣布了一个新的人工智能悬赏计划,专注于基于AI的Bing体验,奖励高达15000美元。利用人工智能驱动的Bing体验作为新漏洞赏金计划的第一个范围内产品,安全研究人员可以提交在以下合格服务和产品列表中发现的漏洞:站长网2023-10-13 11:11:190000TextBase:简易且更懂人话的AI聊天机器人框架
最近,在GitHub上出现了一款名为“TextBase”的产品,这引起了用户的广泛关注。TextBase是一款简单的框架,用于构建AI聊天机器人,它可以帮助开发人员快速搭建和优化聊天机器人。项目地址:https://github.com/cofactoryai/textbase站长网2023-09-05 11:07:290000