上海AI实验室、Meta联合开发开源模型 可为人体生成3D空间音频
要点:
上海AI实验室和Meta联合开发的开源模型能够为人体生成3D空间音频,实现身临其境的3D音场效果。
该模型利用头戴式麦克风的音频信号和人体姿态作为输入,通过多模态融合模式解决音源位置未知、麦克风距离音源较远等技术难题。
尽管取得了在3D空间音频生成方面的技术突破,但目前仅适用于渲染人体音,难以处理非自由音场传播环境,计算量较大难以部署到资源受限的设备上。
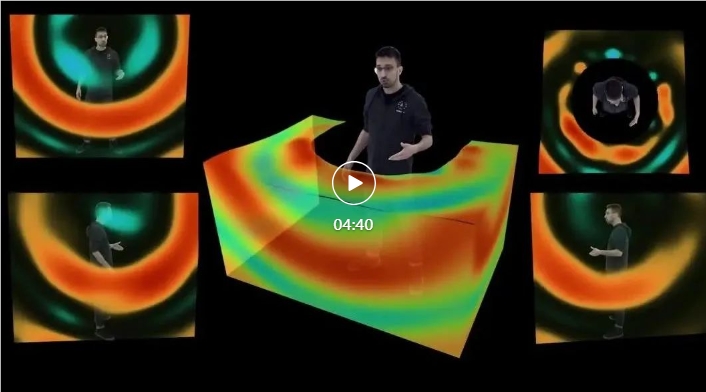
近期上海AI实验室与Meta合作推出的开源模型标志着在3D空间音频领域迈出的一大步。该模型通过处理头戴式麦克风的输入音频信号和分析人体姿态关键点,成功地实现了为人体生成3D空间音频的目标。这一技术突破为虚拟环境的沉浸感和临场感提供了关键支持,弥补了目前学术界和企业在听觉方面的疏漏。
然而,从技术层面看,开发这样的3D空间音频模型并非易事。文章指出,面临着三大技术难题,其中包括音源位置未知、麦克风距离音源较远等挑战。为了解决这些问题,研究人员创新性地构建了多模态融合模式,并引入了身体姿态信息,从而成功消除了声源位置的歧义,实现了正确的空间音频生成。
具体而言,模型包括音频编码器、人体姿态编码器和音频解码器等模块。音频编码器处理头戴式麦克风的输入音频信号,通过时间平移对齐不同身体部位的音源位置,最终得到包含各个可能音源位置信息的音频特征表达。人体姿态编码器则分析人体姿态关键点,生成姿态特征表达,为正确生成三维空间音频提供了重要的提示。
项目地址:https://github.com/facebookresearch/SoundingBodies
尽管该模型在技术上取得了显著进展,成功实现了身临其境的3D音场效果,但研究人员也指出了其局限性。目前,该模型仅适用于渲染人体音,难以处理非自由音场传播环境,且计算量较大,难以在资源受限的消费类设备上部署。这一点对于模型的实际应用和推广提出了一定挑战。
综合而言,上海AI实验室和Meta联合开发的这一开源模型为人体生成3D空间音频开辟了新的可能性,为虚拟现实领域的发展贡献了有力的技术支持。然而,未来仍需进一步优化和拓展,以满足更广泛的应用场景和设备要求。
开源大模型平台Hugging Face获17亿元融资,估值328亿元
8月25日,著名开源大模型、数据集平台HuggingFace获得2.35亿美元(约17亿元)D轮融资,估值达到45亿美元(约328亿元)。本次投资包括Salesforce、谷歌、英伟达、AMD、高通、英特尔、IBM、亚马逊等科技巨头。站长网2023-08-26 17:26:190005完美世界CEO称AI会对电竞有极大赋能 很多职业选手都有AI陪练
在ChinaJoy游戏展上,完美世界联席CEO兼总裁、完美世界游戏CEO鲁晓寅表示,游戏可以成为实体经济的动力,推动创新增长。他介绍说,游戏已经跨越行业,在智慧城市、文化旅游、文物保护、医疗健康、工业生产等方面发挥着作用。在生产环节优化方面,AI技术也在策划、编程、美术等方面提供了帮助,加速了工作效率,缩短了研发周期,降低了游戏制作成本。站长网2023-07-27 17:09:190001网易称雀巢不该推卸责任 雀巢“二手制冰机”事件持续蔓延
近日,网易此前向国家市场监管总局举报雀巢及其代理商提供的二手制冰机存在安全隐患,引发关注。15日,这起事件出现新进展。网易再次发声强调,雀巢作为一级代理商监管方,应承担起安全风险管控责任,不该将责任推卸。网易称,雀巢不应将责任转嫁给代理商,而应对代理商的违规行为予以处罚或公示。同时,网易已将从雀巢采购的咖啡粉送检,以保证员工食品安全。站长网2023-11-15 18:51:010000李国庆称ChatGPT替代不了阅读 后者可以安慰心灵
据《中国企业家》杂志消息,在4月23日的一次读书活动中,当当网创始人李国庆分享了他的观点。李国庆认为,ChatGPT无法取代阅读的作用。阅读不仅可以让人的内心得到平静,也是一种审美享受,这些都是ChatGPT所无法替代的。此外,在晚上睡不着的时候,阅读文学作品能够安慰心灵。而阅读的另一个重要作用则是帮助人们求道解惑。通过阅读,人们可以以较低的成本获得各种知识,这是最有价值的一种投资。站长网2023-04-23 17:34:210000AI视野:ChatGPT和API发生重大中断;GPTs分阶段推出计划延迟;中国第二批11个大模型备案获批;阿里将开源720亿参数大模型
📰🤖📢AI新鲜事ChatGPT和API发生重大中断!11月9日凌晨,OpenAI在官网发布,ChatGPT和API发生重大中断,导致全球所有用户无法正常使用,宕机时间超过2小时。OpenAI已经找到问题所在并进行了修复,但仍然不稳定,会继续进行安全监控。【AiBase提要】⚠️宕机持续时间超过2小时🔍OpenAI已找到并修复问题🔄系统仍然不稳定,继续进行安全监控站长网2023-11-09 15:43:000000