阿里云发布多模态大模型Qwen-VL-Max版本 性能比肩GPT-4V
站长网2024-01-26 11:32:140阅
阿里云公布了多模态大模型的最新研究成果,继Plus版本之后,再次推出Max版本。
Qwen-VL-Max模型在视觉推理方面展现出卓越的能力,可以理解并分析复杂的图片信息,包括识人、答题、创作和写代码等任务。此外,该模型还具备视觉定位功能,可根据画面指定区域进行问答。
在基础能力方面,Qwen-VL-Max能够准确描述和识别图片信息,并根据图片进行信息推理和扩展创作。这一特性使得该模型在多个权威测评中表现出色,整体性能堪比GPT-4V和Gemini Ultra。

在文档分析(DocVQA)、中文图像相关(MM-Bench-CN)等任务上,Qwen-VL-Max同样超越了GPT-4V,达到了世界最佳水平。
此外,Qwen-VL-Max在图像文本处理方面也取得了显著进步,中英文文本识别能力显著提高。该模型支持百万像素以上的高清分辨率图和极端宽高比的图像,不仅能完整复现密集文本,还能从表格和文档中提取信息。
目前,Qwen-VL-Plus和Qwen-VL-Max限时免费向用户开放。用户可以在通义千问官网、通义千问APP直接体验Max版本模型的能力,也可以通过阿里云灵积平台(DashScope)调用模型API。
0000
评论列表
共(0)条相关推荐
拍照可测脱发等级 支付宝上线AI毛发自测工具
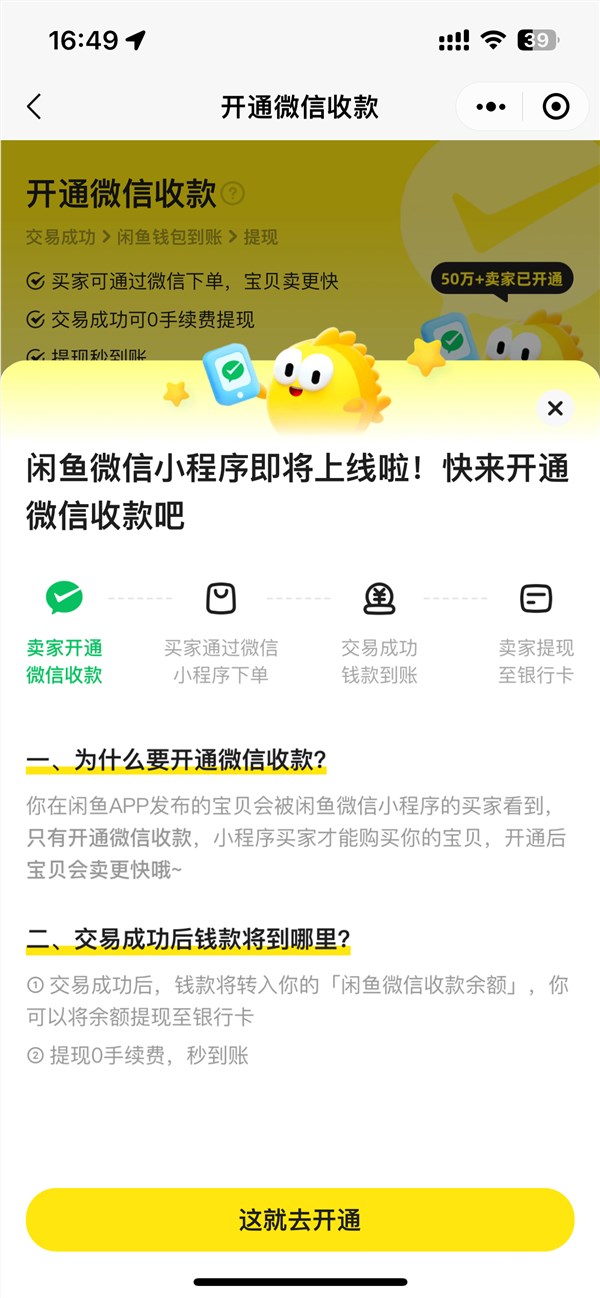
根据国家卫健委此前公布的数据,我国超过2.5亿人有脱发困扰,平均每6人中就有1人脱发,且近些年来,脱发群体呈年轻化趋势。为了帮助应对“秃”如其来的脱发问题,今日,支付宝发布“AI毛发自测”工具,用户只需上传几张头皮照片,即可通过AI大模型能力识别脱发类型、级别并给出健康建议,上支付宝搜索“毛发检测”即可体验。站长网2024-06-06 17:20:560000闲鱼微信小程序上线 购买需商家开通微信收款
近日,微信中已可搜索到闲鱼微信小程序,并且已经正式上线。该小程序覆盖了手机数码、奢品、文玩等多个类目。然而,若要在闲鱼微信小程序上购买商品,需要商家先开通微信收款功能。根据开通微信收款页面显示,交易成功后,钱款将转入商家闲鱼微信收款余额。商家可将此余额提现至银行卡,并声称0手续费,秒到账。站长网2024-01-25 17:39:2400002024年以AI为中心的企业增长的11个数据预测
2023年主要集中在采用生成式人工智能和基础模型。然而,随着组织竞相将生成式人工智能置于工作流的前沿,它们意识到整理数据事务的重要性。尽管企业始终理解高质量数据在业务成功中的作用,生成式人工智能的崛起强化了其价值,确保它成为所有人关注的焦点。现在,随着我们进入2024年,这一年将带来更大规模的生成式人工智能故事,领先的行业专家和供应商分享了他们对数据生态系统不同方面未来几个月发展的预测。0002Factory旨在利用人工智能自动化软件开发生命周期
要点1.Factory是一家旨在利用AI自动化软件开发生命周期的公司,其Droids系统用于执行软件工程中的重复、枯燥但通常耗时的任务。2.Factory的Droids系统包括代码审查、代码重构、生成新代码等任务,旨在提高开发效率和减轻工程师的负担。3.Factory计划长期培训自己的AI模型,以构建完全自动化的工程AI系统,以满足客户需求并提高软件工程的可访问性。站长网2023-11-03 18:19:180001AI耳机开年大战:谁卖爆?谁尴尬?
前两天的“科技春晚”CES2025上,除了AI眼镜的展台被围得水泄不通之外,AI耳机的展台前也大排长龙。随着AI行业的爆发,AI的入口争夺战成为这两年的一大浪潮,AI耳机是不输于AI眼镜的一大市场。目前市面上,手机厂商、音频品牌和互联网大厂及科技公司,都在下场做AI耳机。据「定焦One」不完全统计,目前市面上销量稳定且真正具有AI功能的耳机品牌,已经不下14家。AI耳机火热的背后有两大前提。0000