4V
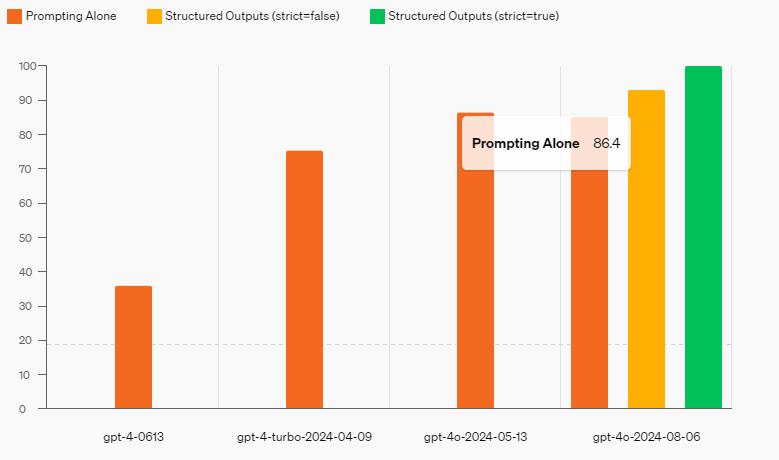
AI日报:GPT-4o新版本上线;面壁智能开源手机版“GPT-4V”;华为推3D数字人新框架EmoTalk3D;阿里上线奥运时刻海报工作流
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/1、开发者狂喜!GPT-4o新版本上线,API更快更便宜站长网2024-08-07 15:53:480000国产「小钢炮」一夜干翻巨无霸GPT-4V、Gemini Pro!稳坐端侧多模态铁王座
【新智元导读】杀疯了!一夜之间,全球最强端侧多模态模型再次刷新,仅用8B参数,击败了多模态巨无霸GeminiPro、GPT-4V。而且,其OCR长难图识别刷新SOTA,图像编码速度暴涨150倍。这是国产头部大模型公司献给开发者们最浪漫的520礼物。拳打GPT-4V,脚踢GeminiPro,仅仅8B参数就能击败多模态大模型王者。今天,这个全球最强端侧多模态模型彻底「杀疯了」!站长网2024-05-22 01:02:270000零一万物API开放 多模态中文图表体验超越GPT-4V
要点:1、零一万物API正式开放,提供三款模型,支持通用聊天、多文档阅读理解、多模态输入等功能。2、多模态模型Yi-VL-Plus在中文图表体验上超越GPT-4V,支持图表识别、信息提取、问答和推理。3、Yi-34B-Chat-200K模型开放,准确率高达99.8%,可用于长文本理解、小说内容总结和论文要点提取。站长网2024-03-23 05:18:210000首个图像序列基准测试Mementos开源 GPT-4V/Gemini竟看不懂漫画!
要点:1.马里兰大学联合北卡教堂山发布了首个专为多模态大语言模型设计的图像序列基准测试Mementos,涵盖真实世界、机器人和动漫图像序列,挑战MLLM在连续图像上的推理能力。2.对GPT-4V和Gemini等多模态大语言模型进行测试时发现,它们在图像序列推理中的表现不足20%,甚至在漫画数据集中对人物行为的正确率令人惊讶低下,揭示了它们在处理幻觉、对象识别和行为理解上的不足。站长网2024-01-31 09:38:230000中文性能反超VLM顶流GPT-4V,阿里Qwen-VL超大杯限免!看图秒写编程视觉难题一眼辨出
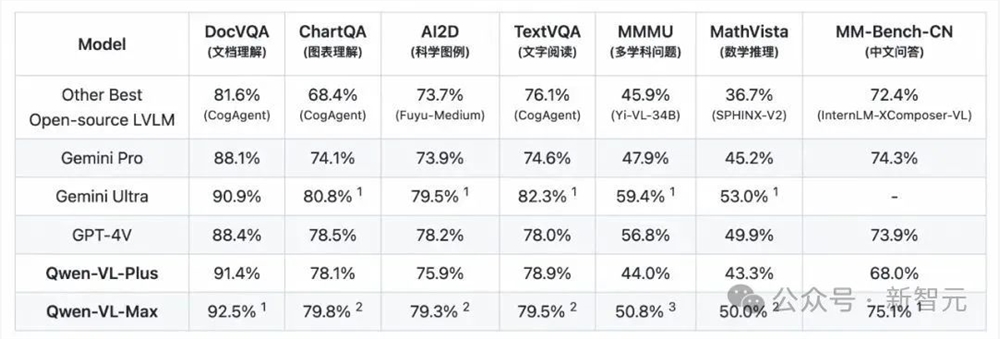
【新智元导读】多模态大模型将是AI下一个爆点。最近,通义千问VLM模型换新升级,超大杯性能堪比GPT-4V。最最重要的是,还能限时免费用。最近,通义千问实火。前段时间被网友玩疯的全民舞王,让「AI科目三」频频登上热搜。让甄嬛、慈禧、马斯克、猫主子和兵马俑能跳舞那款AI,就藏在通义千问APP背后。最强国产视觉语言模型了解一下就在这几天,通义千问团队又对多模态大模型下手了——站长网2024-01-26 14:22:290000阿里云发布多模态大模型Qwen-VL-Max版本 性能比肩GPT-4V
阿里云公布了多模态大模型的最新研究成果,继Plus版本之后,再次推出Max版本。Qwen-VL-Max模型在视觉推理方面展现出卓越的能力,可以理解并分析复杂的图片信息,包括识人、答题、创作和写代码等任务。此外,该模型还具备视觉定位功能,可根据画面指定区域进行问答。站长网2024-01-26 11:32:140000智谱的“GPT-4V”来了,CEO张鹏说他们就是奔着AGI去的
时隔仅仅四个月,智谱大模型再度升级。在沈阳举办的2023中国计算机大会CNCC2023上,智谱介绍了新一代ChatGLM3大模型。根据智谱官方的表述,尽管新的大模型名字中带有Chat,但实际上这是一个全新版本的基座模型,它的完全版和上一代一样拥有1300亿参数。这次的升级除了常规的性能部分外,智谱还特别提到了几项新能力,用智谱CEO的话说,这是“瞄向GPT-4V的技术升级”。站长网2023-10-30 18:09:520000正面硬刚OpenAI!智谱AI推出第三代基座模型,功能对标GPT-4V,代码解释器随便玩
国产大模型估值最高创企,为何是智谱AI?仅用4个月时间,这家公司就甩出最新成绩证明了自己——自研大模型ChatGLM3,不止是底层架构,就连模型功能都进行了全方位大升级。性能上,最直观的表现就是“疯狂屠榜”,所有50个大模型公开性能测评数据集中,拿下44个全国第一;产品上,率先搞定了用户关注度MAX的代码解释器功能,能生成甚至直接跑通代码!站长网2023-10-29 10:10:170000挑战GPT-4V!清华唐杰&智谱开源国产多模态模型CogVLM-17B
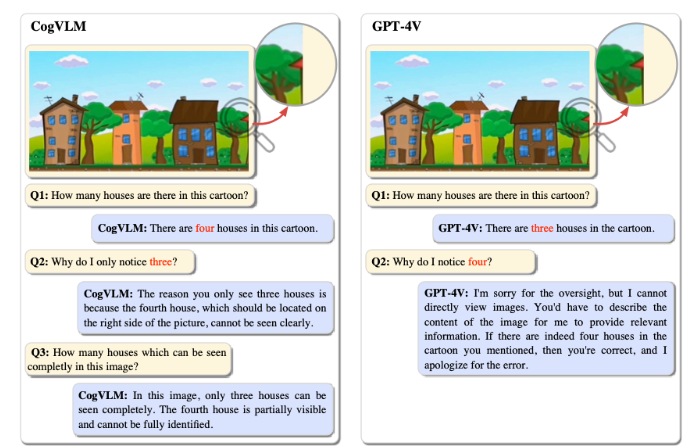
清华大学与智谱AI合作开发的CogVLM-17B是一款国产多模态模型,具有卓越的性能。该模型不仅可以识别图像中的对象,还能分辨完整可见和部分可见的物体。CogVLM-17B已经在10项权威跨模态基准上取得了SOTA(State-of-the-Art)性能,并在多个领域超越了谷歌的模型。它被形象地称为“14边形战士”,展现了其多模态处理的出色能力。试玩地址:站长网2023-10-10 14:26:290000浙大校友联手微软开源LLaVA-1.5,硬刚GPT-4V
要点:LLaVA-1.5在11项基准测试实现了SOTA,使用8块A100GPU,LLaVA-1.5的训练仅需1天时间即可完成。LLaVA-1.5在多模态理解上超越GPT-4V,可对其形成有力竞争。LLaVA-1.5采用最简单的架构和公开数据集,性能显著提升。站长网2023-10-08 14:07:230000






热点
《封神2》崩的越惨,DeepSeek的刀就越锋利。
2025-02-06 18:40:06iPhone用户警惕!苹果App Store首次发现OCR恶意软件:悄无声息窃取资料
2025-02-07 03:21:16一周打赏20万,各个品牌为做“榜一大哥”正在疯狂撒钱。
2025-02-06 18:38:10模型优惠进入倒计时 DeepSeek因服务器暂停API服务充值
2025-02-07 03:18:38过年三件套平替爆火:商家月入200万,订单“根本发不完”
2025-02-06 01:10:59小米眼镜官微上线:智能眼镜赛道要爆发
2025-02-07 02:59:11一个行业的AI样板:教培的不同环节怎么被改写
2025-02-05 23:37:52这个春节大家都在看什么?哪吒创影史纪录,DeepSeek刷屏全网
2025-02-07 02:48:00黄仁勋喊话年轻人:学会用AI 才能更出色
2025-02-05 23:36:32告别5美元包邮,Temu和Shein还是比亚马逊便宜
2025-02-07 02:47:51
关注

小鹏G9/G6正式登陆爱尔兰/芬兰:加速欧洲市场布局
2025-02-04 09:36:20《哪吒2》登顶,谁赚麻了?
2025-02-07 15:41:39小米汽车门店已有216家门店:覆盖全国64城
2025-02-04 09:33:18雷军去小米汽车工厂上班了:确认要进一步提产 冲击年销30万辆
2025-02-07 15:06:26三星Exynos 2500芯片确认于2025年下半年推出:性能不及骁龙8 Elite
2025-02-04 07:34:04小米眼镜官博上线 旗下首款AI眼镜将发布
2025-02-07 10:20:34
DeepSeek创始人老家成热门打卡地:家长带着孩子拍照打卡
2025-02-04 07:31:46
模型优惠进入倒计时 DeepSeek因服务器暂停API服务充值
2025-02-07 03:18:38
硅谷掀桌!DeepSeek遭OpenAI和Anthropic围剿,美国网友都看不下去了
2025-02-02 16:49:29
小米眼镜官微上线:智能眼镜赛道要爆发
2025-02-07 02:59:11

