英伟达发布Nemotron-4:150亿参数通用大模型,目标单张A100/H100可跑
**划重点:**
1. 🌐 Nemotron-4是英伟达最新的通用大模型,拥有150亿参数,在各语言和编码任务中表现出色。
2. 💡 该模型采用Chinchilla模型的「缩放定律」,通过优化计算预算、数据和模型大小实现性能提升。
3. 🔥 在多领域下游评估中,Nemotron-415B超越同等参数规模的模型,甚至击败4倍大的模型,成为最强通用语言模型。
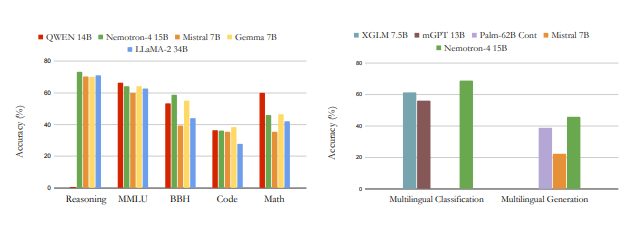
英伟达最新推出的Nemotron-4语言模型引起广泛关注。这一通用大模型拥有150亿参数,经过在8T token上的训练,在英语、多语言和编码任务中表现出色。具体而言,Nemotron-4在7个评估基准上的15B模型表现优异,超越同等参数规模的模型,甚至击败了4倍大的模型。
该模型的设计灵感来自Chinchilla模型的「缩放定律」,该定律强调在给定固定计算预算的情况下,同时优化数据和模型大小。与过去主要关注模型大小不同,这一研究强调将计算分配给更多数据的训练,以降低延迟和服务模型所需的计算量。因此,Nemotron-4的主要目标是打造一个能在单个英伟达A100或H100GPU上运行的最佳「通用大模型」。
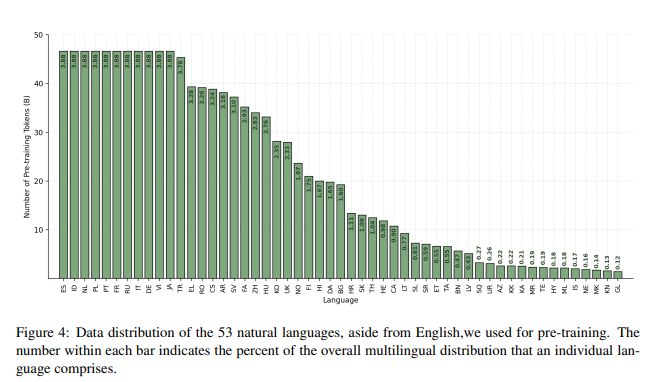
在架构方面,Nemotron-4采用了标准的纯解码器Transformer架构,并带有因果注意掩码。核心超参数包括32亿个嵌入参数和125亿个非嵌入参数。在数据方面,研究人员使用了包含8万亿个token的预训练数据集,分为英语自然语言数据(70%)、多语言自然语言数据(15%)和源代码数据(15%)。
为了实现这一庞大模型的训练,Nemotron-4使用了384个DGX H100节点,每个节点包含8个英伟达H10080GB SXM5GPU。在16位浮点(bfloat16)算术下,每个GPU的峰值吞吐量为989teraFLOP/s。研究人员通过张量并行和数据并行的组合进行训练,并使用了分布式优化器。
在下游评估中,Nemotron-4在各领域均表现强劲,特别是在常识推理、热门综合基准和数学、代码任务上。该模型在多语言分类和生成任务中也实现了最佳性能,展现了其在不同语言的卓越理解能力。值得注意的是,Nemotron-4在机器翻译任务中取得了显著的进展,不仅在中文翻译成英文方面表现出色,而且在中文直接翻译成其他语言方面也取得了印象深刻的效果。
Nemotron-4的推出标志着英伟达在通用大模型领域的一次重要突破,为单个A100或H100GPU上运行的最佳通用大模型设定了新标准。
论文地址:https://arxiv.org/abs/2402.16819
FF:已收到超300台FF 91限量版免订金预订
贾跃亭旗下FaradayFuture(FF)宣布,在阿布扎比举行FF中东战略发布会后72小时内,已收到300多份FF912.0FuturistaiFalcon限量版的不具约束力的免订金预订。站长网2023-11-28 16:40:060000反转!这是有关快速射电暴的新发现!
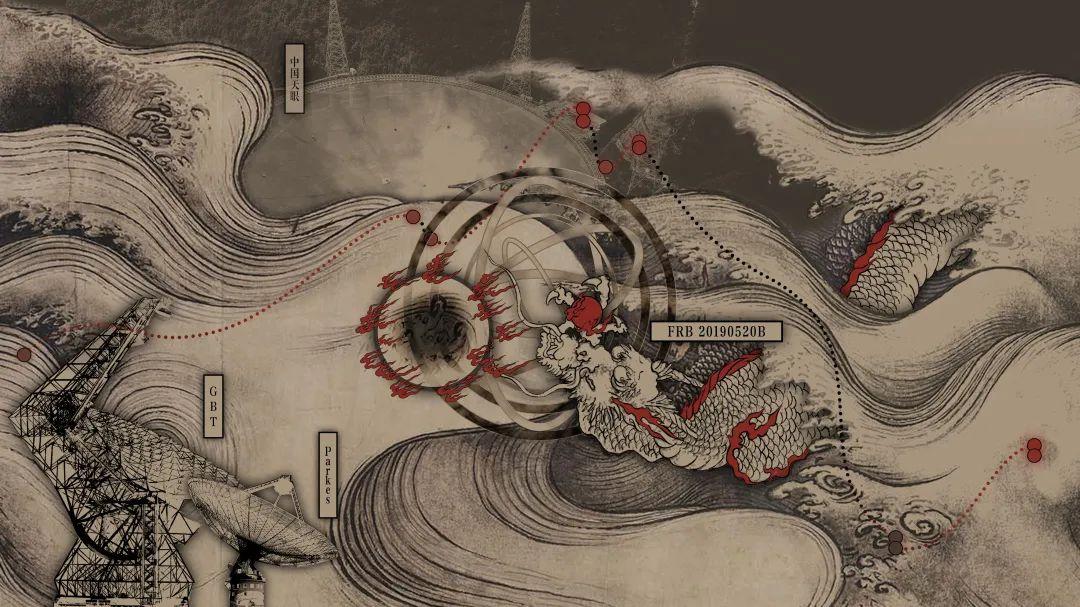
先来看一张图:又有诗曰:散随平野尽,爆入大荒流。星黑双双走,天眼辰星游。江山逐远去,绿岸静默收。宇波涟漪里,宙生又几秋。你可能会好奇:这龙、这环状火焰代表什么?为何会与中国天眼FAST同屏出现?首联化用李白《渡荆门送别》的诗,又暗藏什么玄机?首先说明,上图的环状火焰象征黑洞,FRB是快速射电暴(FastRadioBursts)的英文缩写。站长网2023-05-24 21:58:320000无忧、遥望、谦寻、交个朋友,谁是第一明星直播MCN?
这一次,MCN实现质的飞跃,成为了电视台的买单方。4月16日,无忧传媒的年会“无忧之夜”在浙江卫视播出,而无忧传媒也成为了少数登上星级电视台,搞起品牌定制晚会的MCN。一定程度上,这归结于近几年来,无忧传媒旗下多次出现刘畊宏、张大大等明星在抖音成为现象级顶流的案例。随着网红与明星之间的界限逐渐模糊,背后运营者MCN从中掌握了话语权。站长网2023-04-22 07:31:220007国产本地大模型工具FlashAI发布企业版,一台部署,内网所有电脑可用
FlashAI是一款能在个人电脑免费一键部署本地大模型私有知识库的工具软件,支持win和mac,数十种开源模型可选,可视化界面,无需任何技术知识,开箱即用。其自带的私有知识库可上传pdf,docx,txt,md文档,数据永不离开本机,完全本地训练,提供本地大模型使用,能最大程度保护隐私安全.站长网2024-07-24 01:35:220007老匡:0门槛,月销5万+的“老年人直播”生意怎么做?3个案例,直接抄!
在7月11号的文章里,老匡说“老年人”很可能是仅剩的,现在与未来高速增长的红利赛道。对比年轻人的服装鞋帽、护肤品等大众消费品市场,老年人生意往往具有需求明确、消费能力强、粘性高、易转化等天然优势。这些优势,在抖音直播销售渠道,体现的淋漓尽致。站长网2023-07-26 11:57:540005