Hugging Face AI 平台中发现100个恶意代码执行模型
划重点:
⭐ 研究人员在 Hugging Face AI 平台上发现大约100个恶意机器学习模型,可能让攻击者注入恶意代码到用户机器上。
⭐ 恶意 AI 模型的工作原理:利用 PyTorch 模型等在 Python 和 AI 开发中的方法,可以执行恶意代码。
⭐ 为了减轻恶意 AI 模型带来的风险,AI 开发者应当利用新工具,如 Huntr,来提高 AI 模型和平台的安全性。
研究人员发现,大约有100个机器学习模型被上传到 Hugging Face 人工智能(AI)平台,可能使攻击者能够在用户机器上注入恶意代码。这一发现进一步强调了当攻击者操纵公开可用的 AI 模型用于恶意活动时所带来的不断增长的威胁。

JFrog 安全研究发现了这些恶意模型,这是该公司正在进行的研究的一部分,该研究旨在探讨攻击者如何使用机器学习模型来危害用户环境。研究人员开发了一个扫描环境,用于审查上传到 Hugging Face 的模型文件,以侦测和消除新兴威胁,尤其是来自代码执行的威胁。
具体来说,研究人员发现上传到该存储库的模型中藏有恶意载荷。在一个例子中,扫描器标记了一个由用户名为 baller423的用户上传到存储库中的 PyTorch 模型,该模型允许攻击者将任意 Python 代码插入到关键过程中。当模型加载到用户的机器上时,这可能导致恶意行为。
进一步调查 Hugging Face 后,发现了大约100个潜在的恶意模型,突出显示了来自恶意 AI 模型的整体安全威胁的更广泛影响,这要求对恶意 AI 模型进行持续警惕和更积极的安全性。
为了了解攻击者如何利用 Hugging Face 的 ML 模型,需要了解 baller423上传的 PyTorch 模型等恶意 PyTorch 模型在 Python 和 AI 开发中的工作原理。加载某些类型的 ML 模型时可能会发生代码执行,例如使用 “pickle” 格式的模型。这是因为 pickle 文件也可以包含在加载文件时执行的任意代码。
尽管 Hugging Face 具有多项质量内置安全保护措施,包括恶意软件扫描、pickle 扫描和秘密扫描,但它并没有完全阻止或限制下载 pickle 模型。相反,它只标记它们为 “不安全”,这意味着仍然可以下载和执行潜在有害的模型。
此外,值得注意的是,不仅仅是基于 pickle 的模型容易执行恶意代码。例如,Hugging Face 上第二多见的模型类型是 Tensorflow Keras,它也可以执行任意代码,尽管攻击者利用这种方法并不容易。
为了减轻来自被植入恶意代码的 AI 模型的风险,AI 开发者应该利用他们可用的新工具,比如 Huntr,这是一个专门针对 AI 漏洞的赏金平台,以增强 AI 模型和平台的安全性。这种集体努力对于加固 Hugging Face 存储库、保护依赖这些资源的 AI/ML 工程师和组织的隐私和完整性至关重要。
华为鸿蒙生态设备数量已达8亿:覆盖手机、PC等多终端 纯血鸿蒙秋天见
快科技3月16日消息,在2024年华为云华为终端云创新峰会上,华为官方宣布鸿蒙生态设备数量已达8亿(截至2024年年初)。其中包括手机、PC、平板、智慧屏、车机等高频使用终端设备,已有数千个企业和机构启动了鸿蒙原生应用开发。目前HarmonyOSNEXT鸿蒙星河版已经在进行开发者测试,按照余承东的说法,华为将在今年秋天正式推出正式版,Mate70系列应该会是首发预装机型。0001OpenAI与迪拜G42合作,瞄准扩张中东市场
划重点:1.🤖OpenAI与G42达成合作,旨在在中东地区扩展人工智能能力。2.🌍合作计划在G42的专业领域,如金融、能源、医疗和公共服务中,利用OpenAI的生成式人工智能模型。3.💡合作被视为将AI解决方案带入中东地区,并提升全球扩张计划的关键一步。OpenAI与总部位于迪拜的科技控股集团G42宣布了一项新的合作伙伴关系,旨在扩展中东地区的人工智能能力。站长网2023-10-19 11:57:580000淘宝开通“微信支付”,互通还有多远?
近日,“淘宝订单可以直接微信支付了”登上热搜。据淘宝官方客服回应,目前微信支付的功能仅针对部分用户开放,且仅支持购买部分商品时选择。据了解,这一功能将逐步覆盖所有用户。2月27日,伯虎财经通过淘宝实测,发现支付页面尚未出现“微信支付”这一选项。站长网2024-02-28 09:00:530000荣耀Magic6、MagicOS8.0定档:将于1月10日发布
荣耀官方宣布,将在1月10日至11日举行一场重要的新品发布会,届时将正式推出荣耀Magic6系列旗舰手机,并发布MagicOS8.0操作系统。据此前曝光的信息显示,荣耀Magic6是一款足以对标华为超高端旗舰的产品。在这次发布会上,它将正式与公众见面。0000DeepMind研究人员提出ReST算法:用于调整LLM与人类偏好对齐
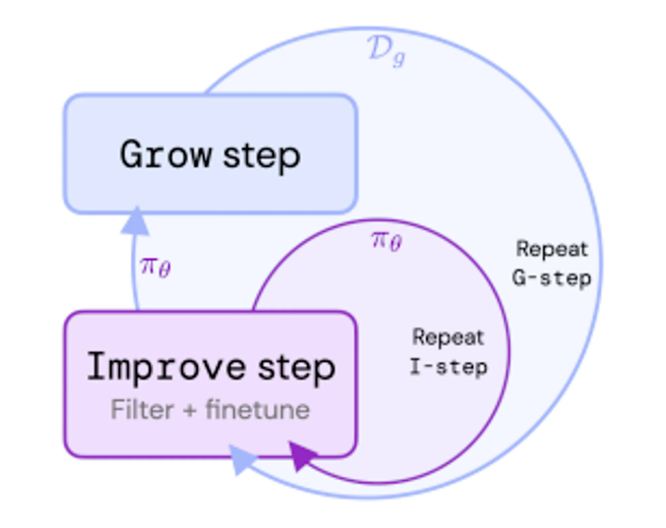
文章概要:1.ReST是一种新方法,通过成长式批量强化学习来调整大型语言模型与人类偏好保持一致。2.ReST使用基于奖励模型的评分函数来过滤策略生成的样本,奖励模型通过学习人类偏好得到。3.ReST内循环使用离线强化学习目标(如DPO)进行策略优化,外循环通过采样增长数据集。站长网2023-08-29 14:27:210001