零一万物API开放 多模态中文图表体验超越GPT-4V
要点:
1、零一万物API正式开放,提供三款模型,支持通用聊天、多文档阅读理解、多模态输入等功能。
2、多模态模型Yi-VL-Plus在中文图表体验上超越GPT-4V,支持图表识别、信息提取、问答和推理。
3、Yi-34B-Chat-200K模型开放,准确率高达99.8%,可用于长文本理解、小说内容总结和论文要点提取。
近日,零一万物API正式向开发者开放,其中包含三款强大的模型。首先是Yi-34B-Chat-0205,支持通用聊天、问答、对话、写作和翻译等功能;其次是Yi-34B-Chat-200K,能处理多文档阅读理解和构建超长知识库;最后是Yi-VL-Plus多模态模型,支持文本、视觉多模态输入,中文图表体验超越GPT-4V。这些模型的开放将促进更广泛的应用场景落地,形成更加繁荣的生态。
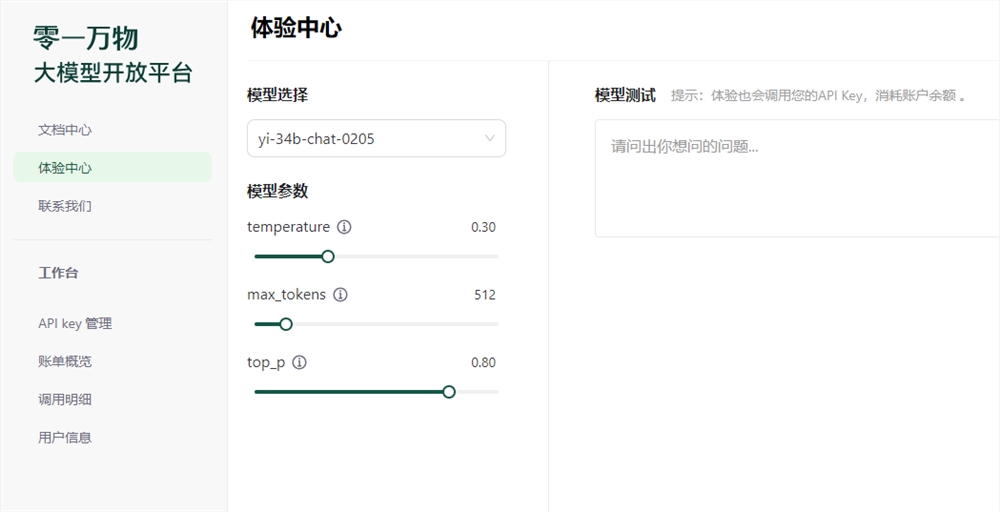
地址:https://platform.lingyiwanwu.com/playground
Yi-VL-Plus作为多模态模型,在中文图表体验上展现出优异的性能,能够识别复杂图表、提取信息并进行推理。相比之下,GPT-4V在这方面表现不佳,例如在处理折线图和饼状图时准确度较低。Yi-VL-Plus不仅可以准确识别图表内容,还能将其转换成其他格式,如markdown。这种多模态能力为用户提供了更加便捷和准确的图表分析体验。
另一款模型Yi-34B-Chat-200K的开放,让大模型应用进入了长文本时代。该模型具有极高的准确率,可用于理解多篇文档内容、分析海量数据和提取关键信息。文学爱好者可以通过该模型快速掌握几十万字小说的精髓,科研人员也可以高效提取论文要点。这种上下文能力的提升,将在各个领域带来更多可能性和便利。
零一万物API的开放为开发者们带来了丰富的宝藏,Yi大模型的强大功能将有助于各种应用场景的优化和提升。无论是在图表识别、文本理解还是长篇文本分析方面,这些模型都展现出了令人惊叹的性能。开发者们赶快来寻宝吧,探索这些API带来的无限可能!
一家年GMV3亿的品牌对直播的反思:警惕起哄,保住基本盘,利润为核心
一年卖货3亿元后,品牌如何持续增长?这是康新牧场急需解决的问题。2006年,康新牧场成立于内蒙古呼和浩特,现在它不仅有年产能3000吨的自有工厂,7000平的自有云仓,还做到了年GMV3亿元,其中抖音渠道占比30%,年GMV在1亿元左右。站长网2023-10-31 09:06:130000苹果已与OpenAI正式达成协议 iOS18将用上ChatGPT
站长之家(ChinaZ.com)5月27日消息:近日,彭博社记者马克・古尔曼(MarkGurman)透露,苹果公司已经与OpenAI达成了一项重要协议,计划为即将发布的iOS18系统带来一系列前沿的生成式AI功能。这不仅标志着苹果在人工智能领域的又一重大突破,也预示着iOS系统将迎来前所未有的智能化升级。站长网2024-05-27 19:35:550000天涯社区回应被申请破产:还在为重启做努力和准备
站长之家(ChinaZ.com)2月28日消息:近日,天涯社区网络科技股份有限公司新增一则破产审查案件,引发广泛关注。据悉,该案件申请人为张鑫,经办法院为海南省海口市中级人民法院。与此同时,天涯社区官网也显示“无法访问”,令众多网友感到惋惜。站长网2024-02-28 15:30:230000浏览量猛增42倍,“MBTI”在小红书爆火
“你是i人还是e人?”最近,这句话成了很多年轻人在社交场合的开场白。与之类似的,还有“f人与t人”、“j人与p人”等略显特别的分类方式。实际上,这些“黑话”均来自火了好几轮的“MBTI人格测试”。MBTI全称“迈尔斯-布里格斯类型指标”,是时下最火的测试工具,一种通过自我问答来确定自身心理偏好的问卷调查。站长网2023-08-16 13:57:030006AI原生3D创作平台Mootion 提供丰富创作场景
Mootion是一款致力于激发用户自然创造力的AI原生3D创作平台。通过先进的人工智能技术,用户可以在虚拟空间中快速生成各种创意的3D场景和动画效果,无需专业的设计技能。体验地址:https://www.mootion.com/landing该平台提供了丰富多样的创作场景,包括舞蹈空间、奇幻森林以及真实的工作室灯光等,让用户可以根据自身需求选择合适的场景进行创作。站长网2023-11-10 18:08:200000