Meta发布全新Megabyte模型 比Transformer快4成
站长网2023-05-30 14:55:390阅
最近,Meta团队开发了一款名为Megabyte的模型,声称能够解决“大模型标配”Transformer所存在的问题,而且速度比它还快4成!
目前,Transformer架构比较流行,但是存在两个重要的缺陷:一方面,自注意力成本随着输入和输出字节长度的增加而迅速增加,如音乐、图像或视频文件通常包含数兆字节,而大型解码器通常只使用几千个上下文标记;另一方面,前馈网络单独对字符组或位置进行操作是难以实现可扩展性的,这是由于在每个位置的基础上会带来很多计算开销。
而Megabyte模型则将输入和输出序列分成patch而不是单个的token。这种架构对于多数任务而言字节预测都相对容易,比如给定前几个字符预测完成单词等,这意味着大型网络中每个字节都是不必要的,并且内部预测可以使用更小的模型进行。这种方法解决了当今AI模型面临的可扩展性挑战,Megabyte模型的patch系统允许单个前馈网络在包含多个token的patch上运算,有效解决了自注意力缩放问题。
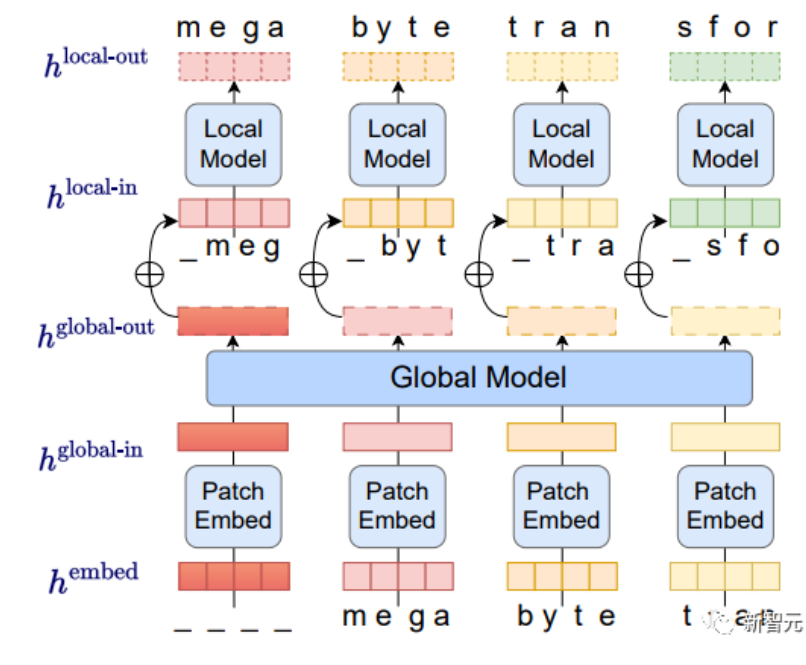
另外,在运算效率方面,与等大的Transformers和Linear Transformers相比,Megabyte在固定模型大小和序列长度范围内使用更少的token,这在相同的计算成本下允许使用更大的模型。
总的来说,这些改进使我们能够在相同的计算成本下训练更大、性能更好的模型,并且可以扩展到非常长的序列,同时在部署期间提高生成速度。综上所述,Megabyte模型的出现提供了一种新的、高效的方法来解决AI模型的发展中出现的一些问题。
论文链接:https://arxiv.org/abs/2305.07185
0000
评论列表
共(0)条相关推荐
携程用私域将订单转化率提升8倍!
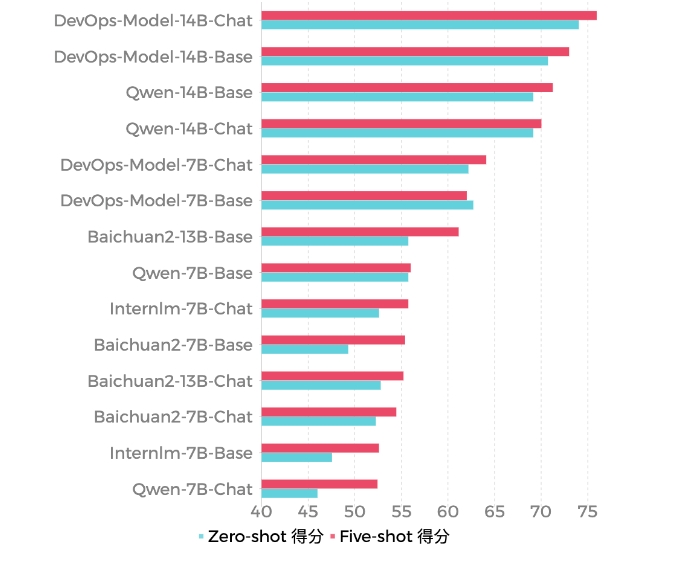
端午节即将到来,你有出行旅游的需求吗?想象一下,在出行前,你需要先在各大平台上不断比价、查攻略、预订酒店和机票。而当你真正踏上旅途,又常常会发现,之前那些看似完美的行程安排,实际上还有很多额外的、临时的需求需要被解决。这时候,如果你的手机里有一个真实的旅行顾问,能根据你的需求提供帮助和一站式服务,那该有多好?站长网2024-06-08 17:02:410000蚂蚁集团开源DevOps领域大语言模型DevOps-Model
DevOps-Model是蚂蚁集团联合北京大学发布的面向中文DevOps领域的大语言模型。该模型通过收集DevOps领域相关的专业数据,并进行语言模型的加训和对齐训练,旨在提供工程师在开发运维生命周期中的效率。DevOps-Model目前已经开源了两种规格的Base模型和Chat模型,并提供了相应的训练代码。站长网2023-11-22 16:39:5100032.5亿美元!谷歌将购买部分HTC XR业务
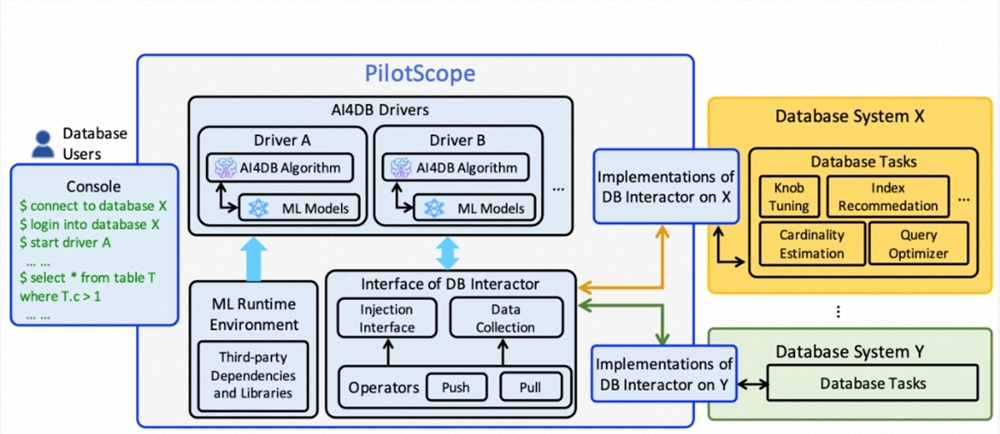
快科技1月23日消息,据报道,谷歌将斥资2.5亿美元与HTC达成一项重要交易,其中部分HTC的XR研发团队精英将融入谷歌大家庭。根据协议条款,谷歌将获得HTC非专属的XR知识产权(IP)授权,这一战略合作的预计完成时间为2025年第一季度。此外,双方还表示将在协议签署后,积极探讨潜在的未来合作契机。0000阿里云免费开源数据库AI算法PilotScope
站长之家(ChinaZ.com)12月20日消息:现有的数据库系统非常复杂,要求非常稳定,即使将单一的AI算法与数据库进行匹配调试,也需要工程师们数周甚至数月的紧密配合,效率低下,效果不佳,导致业界迟迟无法将AI算法应用到数据库中。站长网2023-12-20 15:29:250000苹果财报发布 库克称已在研究人工智能多年
苹果今天举行了2023年第三次财报电话会议。在会议上,苹果首席执行官蒂姆·库克和苹果首席财务官卢卡·马埃斯特里分享了有关最近产品销售、服务业绩、未来计划和收入影响的一些细节。站长网2023-08-04 08:59:010000